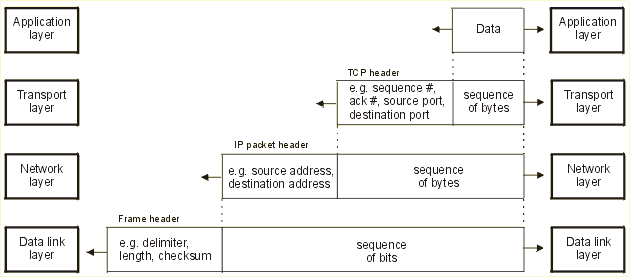
Figure 1: An example of networking layers
Database Group,
Stanford
University
{melnik,stefan}@db.stanford.edu
Revision: Sep 4, 2000
On the Semantic Web, the target audience is the machines rather than humans. To satisfy the demands of this audience, information needs to be available in machine-processable form rather than as unstructured text. A variety of information models like RDF or UML are available to fulfil this purpose, varying greatly in their capabilities. The advent of XML leveraged a promising consensus on the encoding syntax for machine-processable information. However, interoperating between different information models on a syntactic level proved to be a laborious task. In this paper, we suggest a layered approach to interoperability of information models that borrows from layered software structuring techniques used in today's internetworking. We identify the object layer that fills the gap between the syntax and semantic layers and examine it in detail. We suggest the key features of the object layer like identity and binary relationships, basic typing, reification, ordering, and n-ary relationships. Finally, we examine design issues and implementation alternatives involved in building the object layer.
Keywords: layered data modeling, interoperability, object layer
Factors like design independence, competition, purpose-tailoring, and the increasing installed base of software that uses diverse data models suggest that a variety of alternative information models will always be around. Although increasing use of XML has simplified data exchange, the problem of information interoperability remains largely unresolved. For the same kind of data, independent developers often design XML syntaxes that have very little in common. For example, biztalk.org lists a number of XML schemas used to encode purchase orders. In the schema by LCS International Inc., the issue date of a purchase order is specified as:
<PurchaseOrder>
<orderDate>...</orderDate>
</PurchaseOrder>
The encoding chosen by the NxTrend Technology Inc. looks rather like
<PurchaseOrder>
<OrderHeader>
<POIssueDate>...</POIssueDate>
</OrderHeader>
</PurchaseOrder>
whereas the schema by the Open Application Group (OAG) requires yet another incompatible format:
<PROCESS_PO_004>
<DATAAREA>
<PROCESS_PO>
<POORDERHDR>
<DATETIME>...</DATETIME>
</POORDERHDR>
</PROCESS_PO>
</DATAAREA>
</PROCESS_PO_004>
An alternative strategy that is used for reconciling XML data is based on intermediate conceptual models [DMH+00]. In this case, a human expert is needed to reverse-engineer the underlying conceptual model for every XML schema, and to specify formally how the original schema maps onto the corresponding conceptual model. After this step, the differences between conceptual models can typically be bridged with less effort. Although more elegant, this approach has, however, difficulties comparable to the first one. That is, intervention of a human expert is required, and the mappings need to be maintained.
Today's information exchange resembles a group of people communicating by means of encrypted data without disclosing the keys needed to decipher it. A way of reducing the tremendous effort needed for data interoperation is to supply metadata needed to interpret the exchanged information. However, the semantics of XML elements used by Web applications is hard-coded into the applications and is typically not available in machine-processable form. In fact, explicit and comprehensive encoding of metadata is prohibitive for all but rare application scenarios. It is not even clear how much metadata is sufficient, and how it should be encoded. Thus, establishing interoperation is a complex task, with many special-case solutions. Solving the interoperability problem on a broad scale requires novel techniques.
Analogously, if attacked directly, data exchange requires tremendous effort. Any two applications have to be prepared to deal with various encoding syntaxes, different ways of representing objects, ordered and n-ary relationships, aggregation, specialization, cardinality constraints, ontology languages etc. To harness the complexity of data interoperation, we suggest a software structuring technique similar to that used in internetworking. We noticed that existing and emerging data models also tend to be organized in a layered fashion. For example, the Resource Description Framework [LaS99] uses XML as its serialization syntax. RDF itself can be deployed as an object model for carrying UML data [Mel00]. Finally, UML is used as a basis for the Open Information Model (OIM) developed by the Meta Data Coalition. Currently, such ad hoc layering approaches lack well-defined separation between data modeling layers, have redundant features on different layers, and are generally characterized by a very low granularity of layering. We believe that clean separation between the layers can significantly improve data interoperation and facilitate applicability of well-established internetworking principles like bridges and gateways.
In this paper we focus on the question how to identify and distinguish data modeling layers from each other. We start with an analysis of existing data modeling languages and try to extract modeling primitives used in those languages. We roughly organize these modeling primitives into three major layers, the syntax, object and semantic layer, and examine the object layer in more detail. We do not claim that the resulting organization is perfect and definitive. Rather, it is a first incremental step in our effort to build a comprehensive data interoperation architecture.
The next section describes our layered reference model, which we call Information Model Interoperability (IMI) Reference Model. We highlight the design choices that need to be made in providing a clean separation between the data modeling layers and sublayers. In Section [4] we review some popular data models used for data exchange on the Web and justify our design choices. In the rest of the paper we focus on the features and implementation of the object layer.
Figure 1: An example of networking layers
In the figure, the application layer passes the data to the transport layer. The transport layer arranges the data into segments and appends a TCP header to each segment. The header contains metadata about the segment like its sequence and acknowledgement number, source and destination port etc. The TCP header and data are passed further down to the network layer. The network layer arranges segments into packets and appends its own headers to them. Finally, the data link layer sends the data over a physical medium as a sequence of bits, preceded by a frame header. The frame header contains, for instance, a delimiter, number of bits and the checksum of the frame. This information is required to identify frames in a bit sequence. On the other side of the wire, the process is reversed. Each layer receives data from the layer below it, and evaluates the header containing information on how to interpret the data field.
Every pair of adjacent layers exchange information using an interface. The interface defines which primitive operations and services the lower layer offers to the upper one. Clean-cut interfaces make it simpler to replace the implementation of one layer with a completely different implementation and minimize the amount of information that must be passed between layers. In our example, the data link layer may equally well be implemented using the Ethernet or the Token Ring protocol. This design choice does not affect the upper layers. It is not even necessary that the interfaces on all machines in a network be the same, provided that each machine can correctly use all the protocols. For instance, a UNIX application may use Berkeley sockets, whereas a Windows application may use the Winsock library. The only important issue for a successful multilayer communication is an agreement on the protocol stack, i.e. which kind of protocol is used on every layer.
Now, let us turn to data modeling. Imagine two applications that need to exchange complex data. Instead of forcing every application to deal directly with the details of semantics, structure and serialization of data, we can organize the data exchange software in a layered fashion, similarly to the approach taken in the internetworking. Consider a sample set of layers depicted in Figure [2]. In the application layer, the data may be accessed using high-level primitives like "employee.setEmployer(boss)". As in the networking architecture, the data is not exchanged directly between two peer layers. Instead, every layer appends metadata needed to correctly interpret the data, and passes them to the layer below it.
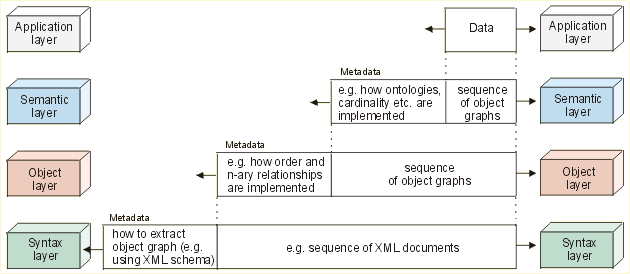
Figure 2: An example of data modeling layers
In the example depicted in the figure, the semantic layer creates an object graph representing the entities and their relationships. It appends to the object graph the metadata needed to determine which ontology languages and ontologies are used, how they are implemented, how cardinality, aggregation etc. are expressed, and passes both the data and metadata to the object layer. The metadata appended at the object layer describes e.g. how ordered relationships or n-ary relationships are implemented, or how typing of nodes is represented in the object graph. This information is forwarded to the syntax layer, which generates, for example, an XML document containing the object graph, and appends to it an XML schema needed to extract the object graph from the document.
On the other end of the communication link, the process is reversed and a high-level data structure is delivered to the application layer. Similarly to internetworking, every data modeling layer relies on a number of rules and conventions to exchange information with its peer, just as two corresponding networking layers deploy a specific communication protocol. For example, the syntax layer may require that the metadata be represented using the XML Schema standard. We call a list of such "protocols" (sets of conventions) a model stack. In our reference model, every data modeling language like UML, RDF etc. can be viewed as a specific model stack.
Obviously, implementing layered data interoperation has a number of challenges. Often a clean-cut distinction between layers or features is not possible. Furthermore, mutual dependencies between the layers may exist. For example, n-ary relationships may be implemented using ordered relationships, or the other way around. Further challenges include the choice of flexible and powerful APIs for every layer, building data gateways for existing data models etc.
As we will demonstrate in the following sections, every layer, or feature like "ordered relationships", can be logically implemented in a number of ways. Given n such features with m options each, this yields mn possible incompatible model stacks, or data models. Clearly, direct interoperation between mn data models is a tedious task that may require as many as O(m2n) mappings between data models. This is exactly the obstacle that today's information integrators face. In fact, in current data modeling languages, the distinction between data modeling layers is blurred. Many standards like UML or XML Schema attempt to capture as many features as possible, reaching from the definition of syntactic elements to aggregation, class partitions, ontology languages etc. As a result, interoperation is exacerbated.
Using a layered approach sketched above, interoperation between data models can be simplified by an order of magnitude. Indeed, if every layer has m implementation options, only O(m2) mappings within a given layer are required in worst case. For n layers, this yields O(nm2) mappings, compared to O(m2n). This simple quantitative analysis explains the tremendous success of layered internetworking. In computer networks, bridges and gateways are used to interoperate within a given layer like the data link layer. Analogously, data modeling gateways can be deployed to reduce the complexity of data interoperation. We call this approach "interdataworking".
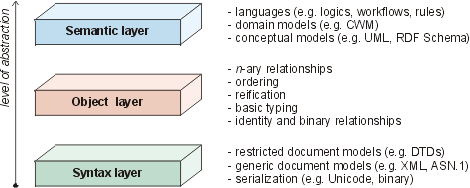
Figure 3: The syntax, object, and semantic layers
Every of the three layers has a number of sublayers. Every sublayer corresponds to a specific data modeling feature, e.g. aggregation or reification, that can be logically implemented in many different ways. Plausible criteria for designing the layers and sublayers include grouping two (sub)layers if they have mutual dependencies, or merging a sublayer that has a single possible implementation option with an adjacent sublayer. In the rest of this section, we briefly describe each of the layers in a bottom-up fashion.
In the past two years we have witnessed how an impressive global-scale agreement on a common syntax layer has been achieved. XML has become pervasive, its use ranging from electronic publishing to electronic business. XML tagging or ASN.1 encoding rules are examples of markup mechanisms for preserving the structure of data. The syntax layer could be divided into three sublayers (bottom-up):
In the discussion of the object layer we are again following a bottom-up approach, i.e. from the ground-level features to more high-level ones. The design issues that we consider in this section have a logical character. They do not necessarily preclude the variety of implementation alternatives at the programming level. Nevertheless, a logical implementation can have major impact on the API design. In Section [6] we briefly examine some programming-level implementation issues.
As long as an application does not need to exchange information with other applications, is does not matter how the objects are identified. In fact, suitable object-oriented APIs may hide the object identity from the programmer completely. To take advantage of the Semantic Web, applications need to communicate, either directly or indirectly by publishing information in machine-readable form. Thus, explicit identifiers for the objects are required. In RDF, objects are identified using the Uniform Resource Identifiers (URIs), a generalized form of Uniform Resource Locators (URLs). A similar approach is taken by SHOE. In UML, objects are identified using Universally Unique Identifiers (UUIDs). OEM allows any unique variable length identifiers. URIs, UUIDs etc. support global identity for the objects, which is a prerequisite for building the Semantic Web.
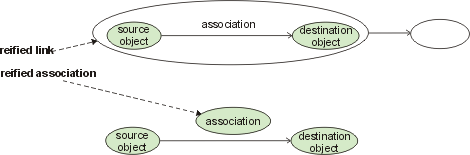
Information models use different abstract notations for binary relationships between objects. In this paper, we adopt the RDF notation. Figure [4] illustrates a binary relationship between a source and a destination object. As a rule, the position of the object in a relationship, i.e. source or destination, is significant. In RDF, every such relationship is viewed as a statement, or assertion. The source and destination objects are the subject and the object of the assertion, respectively.
Figure 4: Abstract notation for a binary link between two objects
In UML, relationships between object instances as shown in the figure are referred to as links. The relationship type, i.e. the relationship as a whole in the semantic layer, is called association. To avoid ambiguity, we follow this terminology.
In OEM, basic typing is used to denote atomic types such as integer or string, and container types such as set or list. Since the "types" themselves are first-class objects, the application can request additional information about the types.
In RDF, the purpose of basic typing is to allow bootstrapping of more complex typing facilities in the semantic layer. In the notation used above, basic typing of an object A using object B is represented as an arc from A to B with a label type that denotes basic typing.
Reification of links and associations is illustrated in Figure [5]. The big oval denotes the object that represents the reified link. In the figure, this object is used as the source for another link. To emphasize reification of the association in the bottom part of the figure, the association is circumscribed as an object. This object can, too, participate in other links. These two kinds of reification provide the necessary prerequisites for computational reflection, i.e. the capability for a computational process to reason about itself [Smi96].
Figure 5: Reification of links and relationships
Both UML and RDF support reification of links and associations. In both standards, link reification is logically implemented by introducing a new object with properties that identify the parts of the link. The logical implementation of link reification in RDF is illustrated in Figure [6].
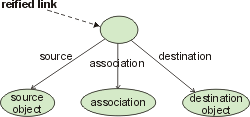
Figure 6: Logical implementation of reified links in RDF
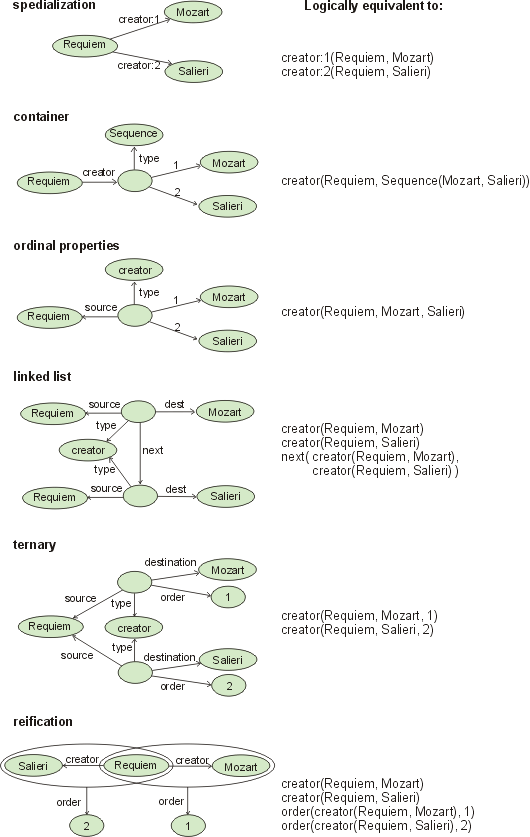
Figure [7] illustrates six logical implementation alternatives for the ordered binary relationship between "Requiem" and the two composers. The right-hand size of the figure presents a "logical" view of the object graphs. The six alternatives are named specialization, container, ordinal properties, linked list, ternary, and reification, according to their logical implementation. Notice that although any representation can be bijectively translated into every other one, they are more or less semantically faithful. For example, the second representation (container) is particularly semantically misleading for representing ordered relationships since it states that the creator of "Requiem" is an object typed as Sequence.
Figure 7: Implementation alternatives for ordered relationships
A qualitative comparison of the alternatives is presented in Table [1]. Besides semantic faithfulness, we consider how difficult it is to use the same logical schema for representing the inverse order. Inverse order is required when the objects at the source end that are related to a single object at the destination end have an ordering that must be preserved. For example, if the "creator" association were to capture the chronological order of the pieces written by the composers, representation for the inverse order would be needed. We gave a minus (-) to the schemes that required creation of additional reified objects for links or associations to support inverse order.
| Alternative | Semantic faithfulness | Inverse order | Implementation effort |
| specialization | ++ | - | -- |
| container | -- | - | -- |
| ordinal properties | +- | - | - |
| linked list | +- | + | + |
| ternary | +- | + | +- |
| reification | + | + | +- |
Table 1: Logical implementation alternatives for ordering
Finally, the last metric that we consider here is the implementation effort. By implementation effort we mean not the effort needed to implement the API that allows manipulating ordered relationships, but the effort needed to use such an API. The typical operations we considered are
In some information and data models, ordering is built-in, i.e. it cannot be reduced to other modeling primitives like reification and binary relationships. Such models include UML, OEM, and XML. In other models like RDF and SHOE, ordering is not a built-in feature and can be implemented in various ways, similarly to the alternatives that we considered above. The choice of alternatives depends on the availability of modeling primitives. For example, since SHOE lacks reification, ordering by reification is out of the question.
Often, n-ary relationships are logically implemented on top of the four sublayers discussed above. Nevertheless, a clear definition of the semantics of n-ary relationships is crucial for interoperability between information models. n-ary relationships cannot be implemented as a combination of binary relationships without using additional objects. Thus, in the object layer, an n-ary link is typically represented as an object that is linked to n objects participating in the link (see Figure [8]).
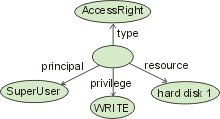
Figure 8: Example of a ternary link
Notice that the logical implementation depicted in the figure does not impose a specific implementation on the programming level. For example, the above ternary link can be implemented as a 3-tuple in a relational database. Using n-ary relationships, however, requires specifically designed API methods.
Some features in the table are marked as implicit. These features, like ordering in UML or n-ary relationships in SHOE, are visible on the API level only. They are not directly represented in the object model.
| Feature | RDF | UML | SHOE | OEM | OIL |
| object identity and binary relationships | + | + | + | + | + |
| basic typing | + | + (implicit) | + (implicit) | + | + |
| reification | + | + | 0 | 0 | 0 |
| ordering | 0* | + (implicit) | 0 | 0* | 0 |
| n-ary relationships | 0 | + | + (implicit) | 0 | 0 |
Table 2: Object layer features in RDF, UML, SHOE, OEM and OIL
*: RDF containers and OEM lists do not carry the semantics of ordered relationships
In our discussion of the object layer we do not intend to pinpoint the "best" logical implementation of each sublayer. It is clear that the designers of different data models may choose one or another option depending on their needs. Thus, in two distinct data models ordering, for example, may be implemented either in a ternary fashion or using reification. Instead of choosing the best option, our goal is to emphasize the usefulness of each sublayer, and provide a roadmap for designing bridges and gateways between similar sublayers in different model stacks.
To illustrate the importance of the design of the object layer, consider the following implementation of ordering using a relational DBMS. In this implementation, a single table tuples holds binary links between objects in a generic fashion. The table contains four fields that represent object identifiers, all fields are of the same type (Object identifiers in a database system are typically implemented as integers. In the examples below we are using stylized string values). The implementation uses order by reification. A sample content of the database is shown below.
ID S
P O
--------------------------------
id1 Requiem creator
Salieri
id2 Requiem creator
Mozart
id3 id1
order 2
id4 id2
order 1
id5 Pinocchio creator Geppetto
The table contains two ordered links and one unordered link. The field ID contains identifiers of reified links. All find-queries listed in Section [5.4] as implementation criteria can be executed using a single SQL query. The most sophisticated query of these is retrieving the first creator. The complicating factor is that some creators are unordered. Still, retrieving the first creator for an object like Requiem can be done using the following single query:
SELECT t1.S, t1.O
FROM tuples AS t1 LEFT JOIN tuples
AS t2 ON t1.ID=t2.S
WHERE t1.S=Requiem AND
t1.P=creator
AND
(t2.P IS
NULL OR t2.P=order) AND
(t2.O IS
NULL OR t2.O=1)
GROUP BY t1.S
The GROUP BY clause is required to reduce the number of multiple unordered creators to one. The first creators of all objects can be retrieved by dropping the first conjunct in the WHERE clause. The result of the query would be:
(Requiem, Mozart)
(Pinocchio, Geppetto)
<tuple ID="id1" S="Requiem" P="creator" O="Mozart"/>
<tuple SID="id1" P="order" O="1"/>
The XML attribute SID in the second tuple is a reference to an ID attribute declared in the first tuple. For even more compact representation, a specialized ordering syntax can be used. Thus, the fact that Salieri is the second creator can be serialized as:
<tuple S="Requiem" P="creator" O="Salieri" order="2"/>
In our approach to structuring the Information Model Interoperability (IMI) reference model we are building on the analogy with the Open Systems Interconnection (OSI) reference model used in computer networks (see [Tan97] for a good summary). One of the major contributions of OSI is to provide a clear distinction between services, interfaces and protocols used in internetworking, enabling a stack of services on top of the more basic levels. Using layering for data modeling includes the following advantages:
On a limited scale, a layered approach to data modeling has been successfully tried in practice. For instance, [Mel00] demonstrates how the semantic layer of UML can be built on top of RDF, and [BKD+00] defines OIL as an extension of RDF Schema on top of the object layer of RDF. Such reuse eliminates effort for defining yet another object model or syntax, and boosts interoperability. As another example, many information models adopted XML for their syntax layers and are able to reuse XML tools and parsers developed by third parties. We believe that a layered approach to data modeling can be an important step toward the realization of the Semantic Web.
| BKD+00 | Jeen Broekstra, Michel Klein, Stefan Decker,
Dieter Fensel, and Ian Horrocks. Adding formal semantics to the Web:
building on top of RDF Schema. Technical Report: Free University of
Amsterdam, 2000,
http://www.ontoknowledge.org/oil/extending-rdfs.pdf |
| Bor85 | A. Borgida: Features Of Languages For The
Development Of Information Systems At The Conceptual Level. IEEE Software,
January 1985
ftp://ftp.cs.rutgers.edu/pub/borgida/CML-features.ps.gz |
| Bra79 | Ronald J. Brachman, On the Epistomological Status of Semantic Networks. In: Findler, Nicholas V. (Ed., 1979). Associative Networks. Representation and Use of Knowledge by Computers. New York: Academic Press, 1979:3-50. |
| BrG00 | Dan Brickley and R.V. Guha (eds). Resource
Description Framework (RDF) Schema Specification 1.0, 2000. W3C Candidate
Recommendation, 2000
http://www.w3.org/TR/2000/CR-rdf-schema-20000327/ |
| Cat91 | R. G. G. Cattell: Object Data Management. Addison-Wesley, 1991 |
| DSS93 | R. Davis, H. Shrobe, and P. Szolovits. What
is a Knowledge Representation? AI Magazine, 14(1):17-33, 1993
http://www.medg.lcs.mit.edu/ftp/psz/k-rep.html |
| DMH+00 | S. Decker, S. Melnik, F. van Harmelen, D. Fensel, M. Klein, J. Broekstra, M. Erdmann, I. Horrocks: The Semantic Web: the Roles of XML and RDF, IEEE Internet Computing, Sept./Oct. 2000 |
| FHH+00 | D. Fensel, I. Horrocks, F. Van Harmelen, S.
Decker, M. Erdmann, and M. Klein. OIL in a Nutshell In: Knowledge
Acquisition, Modeling, and Management, Proceedings of the European Knowledge
Acquisition Conference (EKAW-2000), R. Dieng et al. (eds.), Lecture Notes
in Artificial Intelligence, LNAI, Springer-Verlag, October 2000.
http://www.cs.vu.nl/~ontoknow/oil/downl/oilnutshell.pdf |
| GHW99 | R. Goldman, J. McHugh, and J. Widom. From
Semistructured Data to XML: Migrating the Lore Data Model and Query Language.
WebDB Workshop, 1999
http://dbpubs.stanford.edu/pub/1999-53 |
| HHL99 | J. Heflin, J. Hendler, and S. Luke. SHOE:
A Knowledge Representation Language for Internet Applications.Technical
Report CS-TR-4078 (UMIACS TR-99-71), 1999
http://www.cs.umd.edu/projects/plus/SHOE/pubs/#tr99 |
| HeH00 | Jeff Heflin and James Hendler. Semantic Interoperability
on the Web.In Proceedings of Extreme Markup Languages 2000. 2000
http://www.cs.umd.edu/projects/plus/SHOE/pubs/#extreme00 |
| HFB+00 | I. Horrocks, D. Fensel, J. Broekstra, S. Decker,
M. Erdmann, C. Goble, F. van Harmelen, M. Klein, S. Staab, R. Studer, and
E. Motta The Ontology Inference Layer OIL, Technical Report, Free
University of Asterdam, 2000,
http://www.cs.vu.nl/~dieter/oil/Tr/oil.pdf |
| LaS99 | Ora Lassila and Ralph R. Swick (eds). Resource
Description Framework (RDF) Model and Syntax Specification. W3C Recommendation,
1999
http://www.w3.org/TR/REC-rdf-syntax/ |
| Mel99 | S. Melnik: An API for RDF, 1999
http://www-db.stanford.edu/~melnik/rdf/api.html |
| Mel00 | S. Melnik: Representing UML in RDF, 2000
http://www-db.stanford.edu/~melnik/rdf/uml/ |
| PGMW95 | Y. Papakonstantinou, H. Garcia-Molina, J. Widom:
Object
Exchange Across Heterogeneous Information Sources Proc. Int. Conf.
on Data Engineering (ICDE), 1995
http://dbpubs.stanford.edu/pub/1995-6 |
| Smi96 | Brian C. Smith: On the Origin of Objects. MIT Press, 1996 |
| Sow00 | John F. Sowa. Ontology, Metadata, and Semiotics.
Proc. Int. Conf. on Conceptual Structures (ICCS), Aug 2000
http://www.bestweb.net/~sowa/peirce/ontometa.htm |
| Tan97 | Andrew. S. Tanenbaum. Computer Networks, Prentice-Hall, 3rd ed., 1997 |
| XSLT | W3C: XSL Transformations (XSLT), W3C
Recommendation, 1999
http://www.w3.org/TR/xslt |