Laurence Melloul, Dorothea Beringer, Neal Sample, Gio Wiederhold
Computer Science Department, Stanford University
{melloul@db, beringer@db, sample@cs, gio@db}.stanford.edu
http://www-db.stanford.edu/CHAIMS
Abstract
Software composition is critical for building large-scale applications. In this paper, we consider the composition of components that are methods offered by heterogeneous, autonomous and distributed computational software modules made available by external sources. The objective is to compose these methods and build new applications with no integration, hence decreasing the time and the cost needed for producing and maintaining the added functionality. In the following, we describe a high-level protocol which makes it possible to accomplish such software composition. The CPAM protocol can be used on top of various distribution systems. It offers additional features for dealing with the issues of heterogeneity and autonomy, and implements several optimization concepts such as run-time cost estimation of available methods and partial extraction of results.
Keywords: Software Composition, Protocol for Composition, Distributed
Systems, Autonomous Systems, Optimized Composition
Introduction
CPAM is a high-level protocol for realizing software composition. CPAM has been defined in the context of the CHAIMS (Compiling High-level Access Interfaces for Multi-site Software) research project [1] at Stanford University in order to build extensive applications by composing large, heterogeneous, autonomous, and distributed software modules.
Software modules are large if they are computation intensive or/and data intensive (computation time ranges from seconds in the case of information requests to days in the case of simulations, and the amount of data transmitted can not be neglected). They are heterogeneous if they are written in different languages (e.g., C++, Java), use different distribution protocols (e.g., CORBA [2], RMI [3]), or run on diverse platforms (e.g., Windows NT, Sun Solaris, HP-UX). Software modules are autonomous if they are developed and maintained independently of one another, and independently of the composer who composes them. Finally, they are distributed when they are not located on the same machine server and may be used by more than one client. We will call modules with these characteristics megamodules and the methods they offer services.
Megamodule composition consists in remotely invoking the services of the composed megamodules in order to produce new services. Software composition differs from software integration in the sense that it preserves megamodules' autonomy. Naturally, the assumption is that megamodule providers are eager to offer their services. This is a reasonable assumption if we consider the business interest that would derive from the use of services, such as a payment of fees or the cut of customer service costs.
Composition of megamodules is becoming crucial for the software Industry. As business competition and software complexity increase, companies have to shorten their software cycle (development, testing, and maintenance) while offering ever more functionality. Because of high software development or integration costs, they are being forced to build large-scale applications by reusing external services (the electronic commerce is a way to access services through the Web) and composing them. These services being offered by independent and geographically distant providers, they are therefore autonomous and most likely heterogeneous and distributed. Also, composition becomes critical when services are large because of cost-effectiveness.
Existing distribution protocols such as CORBA(RMI, DCE [4], DCOM [5]) allow to compose software with different legacy codes but using CORBA(DCE, RMI, DCOM) as the only distribution protocol. The Horus protocol [6] composes heterogeneous protocols in order to add functionality, but at the protocol level only. The ERPs, Enterprise Resource Planning systems (such as SAP R/3, BAAN IV, PeopleSoft), integrate heterogeneous and initially independent systems but do not preserve software autonomy.
CPAM, CHAIMS Protocol for Autonomous Megamodules, has been defined for
composing large, heterogeneous, autonomous and distributed software. CPAM
deals with the issues of heterogeneity and distribution, preserves the
autonomy of megamodules, and allows efficient composition of large-scale
services.
1. CPAM deals with the issues of Heterogeneity and Distribution
Composition of heterogeneous and distributed software modules implies several constraints. The composition has to support heterogeneous data transmission between megamodules as well as the diverse distribution protocols used by megamodules.
1.1 Data heterogeneityIn order for megamodules to exchange data, data needs to be in a common format (a separate research project is exploring ways to map different ontologies [7]). Also, data has to be machine and architecture independent (16 bit architecture versus 32 bit architecture for instance), and transferred between megamodules regardless of the distribution protocol at either end (source or destination). For these reasons, The current version of CPAM requires data to be ASN.1 structures encoded using BER rules [8].
With ASN.1/BER-encoding rules:
In the future, another option for a common data format might be the emerging XML (eXtensible Markup Language) standard [9] which maps data to strings.
1.2 Opaque data and visible dataBecause ASN.1 data blocks are encoded, we refer to them as BLOBs (Binary Large OBjects). Before being transported, the data is encoded in the source megamodule. It is then sent to the client where it remains as BLOBs. It gets decoded only when it reaches the destination megamodule.
BLOBs being opaque, they are not readable by CPAM nor by the client using CPAM. A client which does composition does not need to interpret the data it receives from a megamodule or sends to a megamodule. Nevertheless, CPAM allows efficient composition especially by giving a client the possibility of making a decision at any point in the program execution (see section 3 below). Such a decision would very likely be based on the data received. The client must therefore be able to read some of the data received. For this purpose, CPAM allows conversions between BLOBs and simple data types. An intermediate megamodule must be used in order to decode a complex data type as the client is not aware of the underlying data type's structure.
1.3 Distribution protocol heterogeneityWe saw that encoded ASN.1 data was transferred independently of the distribution protocols used by the megamodules. Nevertheless, a distribution protocol influences connections between clients and servers. CPAM is a high-level protocol which uses existing protocols for establishing connections to megamodules and transporting data between clients and servers. Therefore, CPAM specifications may be implemented on top of various distribution systems. Currently, in the context of CHAIMS we have integrated the following protocols: CORBA, RMI, DCE, local C++ and local Java (local qualifying a server which is not remote).
CPAM assumes that the client is able to talk to the servers through their various distribution protocols on whatever operating systems they are using. The CHAIMS architecture, together with CLAM (CHAIMS Language for Autonomous Megamodules) [10], allows the generation of such a client.
1.4 The CHAIMS architecture
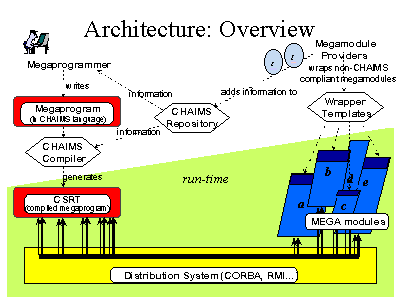
Figure 1 describes the CHAIMS architecture. In CHAIMS, the composer is called the megaprogrammer, the client program is the megaprogram and the compiled program is the CSRT (Client Side Run Time).
The green portion corresponds to the run-time system and includes all elements directly related to CPAM:
Both the client and the servers have to follow CPAM specifications.
As it is noted in figure 1, megamodules which are not CPAM compliant need
to be wrapped. The process of wrapping is described in section 4.2.
2. CPAM preserves Megamodules' Autonomy
Besides being heterogeneous and distributed, megamodules are autonomous. They are developed and maintained independently from the composer which therefore has no control over them. How can the composer be aware of all services offered by megamodules and of the latest versions of these services without compromising megamodules' autonomy? Also, how do the connections and disconnections between the client and the servers take place? Does the client or the server control the connection?
2.1 Information repositoryComposition can not be achieved without knowing what services are offered and how to use them. A software user's guide is generally sufficient to know what the purposes of the services are, but does not contain any implementation details about the services. A programmer's guide does contain some implementation details, but these usually represent static information (parameter names and parameter types, for instance). Megamodules, being autonomous and distributed, make it necessary to retain knowledge of dynamic information (e.g., the names of the machines where the services are located).
CPAM requires that the necessary information, both static and dynamic, be gathered into one information repository. Each megamodule provider is responsible for making such a repository available to external users, and for keeping the information up-to-date.
2.1.1 The information repository's content
2.1.2 The scope of parameter names
2.2 Establishing or terminating a connection with a megamoduleAnother issue when composing autonomous megamodules is the ownership of the connection between a client and a server.
Clients are responsible for making a connection to a megamodule and terminating it; servers must be able to handle simultaneous requests from various clients and must be started before such requests arrive. Certain distribution protocols like CORBA include an internal timer which stops a server execution process if no invocations occur after a set time period and instantly starts it when a new invocation arrives.
CPAM defines two primitives in order for a client to establish or terminate a connection to a megamodule. These are SETUP and TERMINATEALL. SETUP tells the megamodule that a client wants to connect to it; the megamodule generates the necessary internal data structures to handle all future calls from this client. TERMINATEALL notifies the megamodule that the client will no longer use its services; the megamodule kills any ongoing invocations initiated by this client and deletes all related data structures. For both calls, the client is identified with a clientID. If for any reason, a client does not terminate a connection to a megamodule, we can assume the megamodule itself will do it after a time-out and a new SETUP will be required from the client before any future invocation.
The information repository, along with the connection rules, ensures
that a server's autonomy is preserved and that the clients can use the
services offered.
3. CPAM allows Efficient Composition of Large-scale Services
CPAM makes it possible to compose services offered by heterogeneous, distributed and autonomous megamodules. Services being large, an even more interesting objective for a client would be to efficiently compose these services. CPAM allows efficient composition in the following two ways:
Because the invocation cost of a large service is a priori high and services are distributed, a random composition of services could be very expensive. The invocation sequence has to be optimized. CPAM has defined its own invocation structure in order to allow parallelism and easy invocation monitoring. Such capabilities add to the possibility of estimating a method cost prior to its invocation and optimize the invocation sequence in the client.
These four primitives are described below:
3.1.2 Cost estimation
Differences in cost are treated in CPAM as fees (amount of money to pay to use a service), time (time of a method execution) and data volume (amount of data resulting from a method invocation). Since the last two factors are highly run-time dependent, their estimation has to be at run-time as close as possible to the time the method should be invoked. Due to the autonomy of megamodules, the client has no knowledge of or influence over the availability of resources. The ESTIMATE primitive which is offered by the server itself is therefore the only way a client can get most accurate performance and cost information.
The input parameters for ESTIMATE are the clientID of the calling client, the name of the method to estimate and a name list containing the names of the cost parameters the client is expecting (fee, time or/and data volume). Due to the generic nature of the name list, additional parameters like location could be added without changing CPAM. The output parameter of ESTIMATE is a name-value list containing the requested estimates.
Parallelism, invocation estimations and invocation examinations are very helpful functionality of CPAM which, when combined, give enough information and flexibility to get an optimized sequence of invocations at run-time. Another optimization factor in CPAM concerns data flow between megamodules.
Dually, GETPARAM, with the input parameters clientID and a name list, returns client specific settings or default values of parameters and global variables.
3.2.2 Hierarchical setting of parameters
CPAM establishes a hierarchical setting of parameters within megamodules. A parameter's default value defines the first level of parameter settings (see figure 2). The second level is the client specific setting (SETPARAM). The third level corresponds to the invocation specific setting (parameter value provided for one specific invocation with INVOKE). Invocation specific settings override client specific settings for the time of the invocation, whereas client-specific settings override general default values for the time of the connection. When a method is invoked, the megamodule takes the invocation specific settings for all parameters for which the invocation supplies values; for all other parameters, the megamodule takes the client specific settings if they exist, otherwise it takes the general default values.
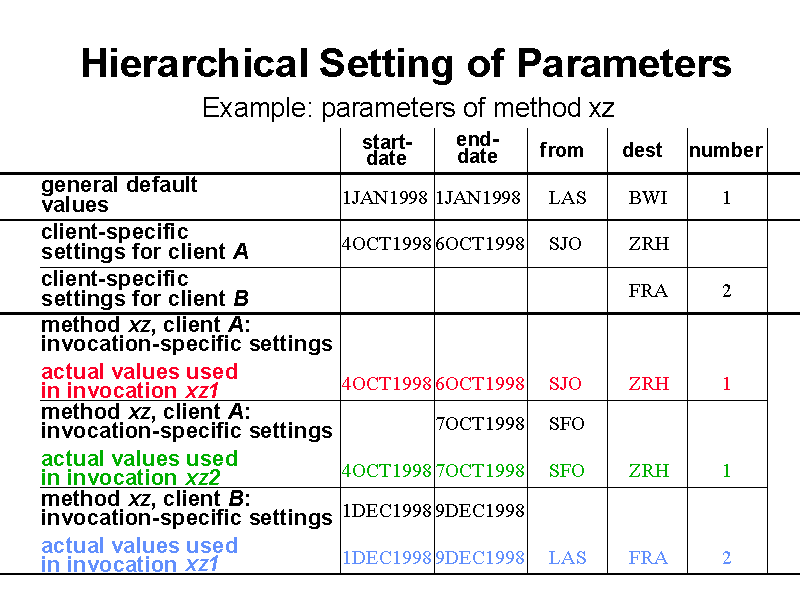
Figure 2. Hierarchical setting of parameters
3.2.3 Partial extraction of results
In conclusion, a client does not need to specify all input data or global
variables in order to make an invocation, nor does it need to retrieve
all available results. This reduces the amount of data transferred between
megamodules and optimizes the communication between the client and servers.
Megamodules being large and distributed, invocation sequence optimization
and data flow minimization are necessary for accomplishing efficient composition.
4. How to use CPAM
We have discussed the various primitives of CPAM necessary to efficiently compose megamodules. Two more points have to be mentioned in order to completely define CPAM and the way composition should be done. The first point concerns the client: how should the invocations be ordered in the client program? The second concerns the server: what needs to be done in order to allow a megamodule which is not CPAM compliant to become compliant and support composition?
4.1. Invocation ordering constraintsFigure 3 summarizes the nine primitives of CPAM, with their ordering constraints.
CPAM primitives cannot be called in any arbitrary order, but there are only two constraints:Figure 3. Primitives in CPAM and ordering constraints
- All primitives apart from SETUP must be preceded by a connection to the megamodule through a call to SETUP which has not yet been terminated by TERMINATEALL,
- The invocation referred to by EXAMINE, EXTRACT, TERMINATE must be preceded by an INVOKE call which has not yet been terminated by TERMINATE.
4.2. The CHAIMS wrapperIn case a server does not comply to CPAM specifications, it has to be wrapped in order to use the CPAM protocol. Below are summarized CPAM specifications.
4.2.1 CPAM specifications and corresponding functionality
| CPAM specification | Functionality provided |
| 1. Information Repository | Autonomy |
| 2. Underlying distribution protocol | Distribution and Heterogeneity |
| 3. ASN.1/BER data | Heterogeneity |
| 4. SETUP, TERMINATEALL | Connection control |
| 5. Invocation structure (INVOKE, EXAMINE, EXTRACT, TERMINATE) | Parallelism, Invocation monitoring, Partial extraction |
| 6. SETPARAM, Parameter name scoping | Presetting and Hierarchical setting of parameters |
| 7. ESTIMATE | Cost estimation |
If a megamodule does not implement one or more of these specifications, it has to be wrapped. CHAIMS wrapper templates allow a megamodule to become CPAM compliant with a minimum of additional work.
4.2.2 The CHAIMS wrapper
Conclusion
CPAM is a high-level protocol for composing megamodules. It deals with heterogeneity and distribution mainly by transferring data as encoded ASN.1 structures. It preserves megamodules' autonomy by collecting services information in an information repository. Most important, CPAM allows efficient composition of large-scale services by optimizing the invocation sequence and minimizing data flow between megamodules. As CPAM is focused on composition, it does not provide support for type checking, recovery or security. These services could be obtained by orthogonal systems or by integrating CPAM into a larger protocol.
A successful utilization of CPAM for realizing composition is the Transportation example implemented within the CHAIMS system. The example consists in finding the best way for transporting goods between two cities. The composer uses services from four heterogeneous and autonomous megamodules. The client program is written in CLAM. It is generated through the CHAIMS compiler and uses CPAM. A second version of the Transportation example is under implementation and will include optimization functionality as cost estimation, partial extraction and qualitative and quantitative invocation examination.
Even more optimization could be achieved by automated scheduling of
composed services which use the CPAM protocol. Automation, while not disabling
optimizations that are based on domain expertise, will discharge the composer
from lower level scheduling tasks. In a large-scale and distributed environment,
resources are likely to be relocated, and their available capacity depends
on aggregate usage. Invocation scheduling and data flow optimization needs
to take into account such constraints. The CPAM protocol gives the necessary
information for allowing automated scheduling of composed software at run-time.
References
[1] G. Wiederhold, P. Wegner and S. Ceri: "Towards Megaprogramming: A Paradigm for Component-Based Programming"; Communications of the ACM, 1992(11): p89-99
[2] J. Siegel: "CORBA fundamentals and programming"; Wiley New York, 1996
[3] C. Szyperski: "Component Software: Beyond Object-Oriented Programming"; Addison-Wesley and ACM-Press New York, 1997
[4] W. Rosenberry, D. Kenney and G. Fisher: "Understanding DCE"; OReilly, 1994
[5] D. Platt: "The Essence of COM and ActiveX"; Prentice-Hall, 1997
[6] R. Van Renesse and K. Birman: "Protocol Composition in Horus"; TR95-1505, 1995
[7] J. Jannink, S. Pichai, D. Verheijen and G. Wiederhold: "Encapsulation and Composition of Ontologies"; submitted
[8] "Information Processing -- Open Systems Interconnection -- Specification of Abstract Syntax Notation One" and "Specification of Basic Encoding Rules for Abstract Syntax Notation One", International Organization for Standardization and International Electrotechnical Committee, International Standards 8824 and 8825, 1987
[9] "Extensible Markup Language (XML), 1.0", Recommendation of the World Wide Web Consortium, February 1998
[10] N. Sample, D. Beringer, L. Melloul and G. Wiederhold: "The coordination language CLAM"; submitted
[11] L. Perrochon, G. Wiederhold and R. Burback: "A compiler for Composition: CHAIMS"; Fifth International Symposium on Assessment of Software Tools and Technologies (SAST `97), Pittsburgh, June 3-5, 1997
[12] D. Beringer, C. Tornabene, P. Jain and G. Wiederhold: "A Language and System for Composing Autonomous, Heterogeneous and Distributed Megamodules"; DEXA International Workshop on Large-Scale Software Composition, August 28, 1998, Vienna Austria
[13] Birell, A.D. and B.J. Nelso: "Implementing Remote Procedure Calls"; ACM Transactions on Computer Systems, 1984. 2(1): p. 39-59
[14] ISO, "ISO Remote Procedure Call Specification", ISO/IEC CD 11578
N6561, 1991
