In large organizations, several independent databases are often used simultaneously in different departments for different purposes. Often the relevent information required for an individual or group to make necessary decisions is spread across two or more of these independent databases, each of which often has its own method for data retrieval and schema representation. Compounding the problem, many of these databases or information sources are often independently owned, making the movement of data from one source to the other or the modification of data or schema unacceptable. Traditionally, solutions to these problems have included delegating one or more individuals or groups to handle all of the information requests or creating a new local database, thus duplicating data owned by another group. Unfortunately, these methods can introduce additional delays and errors due to human-related factors and data synchronization issues.
The Environmental Restoration (ER) organization is part of a larger organization at the Idaho National Engineering and Environmental Laboratory (INEEL) called Environmental Operations. The Environmental Operations organization also includes Waste Management and a Sample Management Office. Over the last 30 years, the three Environmental Operations' organizations and their predecessors have developed more than 100 individual databases to serve individual applications. Within the last ten years, a need has developed to pull data from many of these individual databases and present the selected data as integrated information. These individual databases are contained in flat files, formal relational databases such as Oracle, FoxPro, and dBASE, as well as other proprietary formats. The INEEL Environmental Operations organization needed a method to access these many disparate data sources in a generalized fashion so that the same software could be used for more than one specific combination of data sources.
The INEEL Data Integration Mediation System (IDIMS) was built to address the data integration issues of a specific ER domain at the INEEL. IDIMS was designed and implemented as a collaborative effort among the INEEL, Stanford University, and ISX Corporation. IDIMS provides a method of preserving a group and/or individual's knowledge about how to access and integrate data for a variety of domains. This domain knowledge includes the definition of the domain's integrated view, the specification of how the data sources fit to this view, the knowledge of how to integrate data across the different data sources, and the knowledge required to retrieve data from these sources. IDIMS provides the group with the benefits of consistent application of domain knowledge and the reduction of unnecessary data duplication. IDIMS was designed to accept the domain knowledge as input into the system so the same software can be utilized by many different domains.
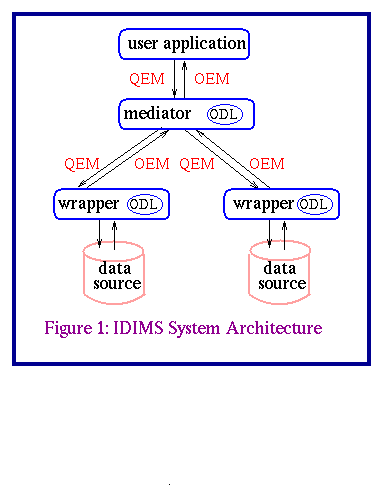
The INEEL ER problem scenario provided the prototype domain for the initial version of IDIMS. It involved integrating data spread across two types of structured databases, Oracle and FoxPro. Due to the fact that most large organization use structured databases for the high performance and comprehensive query support these databases offer, the implemented IDIMS assumes that the data is organized entirely in structured form. Although this is currently the underlying assumption, the IDIMS system architecture was designed to handle a wide range of data source types. To access and integrate data retrieved from non-structured data sources, changes would be needed at the data-access level, but the overall system architecture should remain the same. Figure 1 illustrates the IDIMS system architecture. A similar framework is also used in other mediation systems, such as DISCO[2], GARLIC[3], TSIMMIS[4] and HERMES[5].
There are three subsystems in IDIMS: the user application, the mediator, and the wrapper. As Figure 1 shows, a mediator serves as a middle-layer which provides data access and data integration to a user application so that the user application does not need to distinguish the differences among the data sources. Instead, the user application perceives a central object-oriented database provided by the mediator. When a mediator receives a user query, it decomposes the query into sub-queries (if necessary) and forwards the sub-queries to the correct wrapper(s). A wrapper provides the mapping from the mediator's integrated view to its specific data source view. A wrapper receives queries from a mediator and translates the queries into the source-specific query language and terminology. The query results are returned from the wrapper(s) to the mediator. The mediator then integrates all the results and returns a single response to the user application.
Even though IDIMS was initially built to address the problem in the INEEL ER domain, the system was designed to be domain-independent. In other words, it was designed so that a variety of domains could utilize IDIMS' data integration capabilities as long as the appropriate domain knowledge is provided.
In order to provide domain independence, extensibility, and flexibility, the following four elements are critical to IDIMS:
An extended version of the ODMG (Object Database Management Group) ODL (Object Definition Language) [6] is used for both the mediator and the wrapper subsystems to describe their specific views of the domain. This method of domain specification allows the domain knowledge to become a dynamic input into IDIMS.
Every wrapper and mediator subsystem shares a common service interface. The most commonly used services include accepting a query, returning data results, and providing schema-related information. This common service interface allows for the dynamic extension of the number of available wrappers and/or addition of vertical mediator layers to the system without modifying the system architecture or software.
A new query structure, Query Exchange Model (QEM), was defined for IDIMS to provide a common query representation used by each of the IDIMS subsystems.
The Object Exchange Model (OEM) [7] was adopted as the common data representation for IDIMS. OEM is simple and flexible, facilitating data integration across multiple data sources.
In the body of this paper, we provide details about the mediator and wrapper components, along with their supporting Semantic Model libraries and their QEM and OEM structures. We will not address the user application component beyond describing how it interfaces with the mediator component. In the conclusion of this paper, we provide an assessment of the whole system and discuss some related work that has been done in this area.