DAML (OntoAgents)
Homework Assignment 2:
DAML Queries/Life Cycle
|
<namespace-declarations> |
FORALL X, Y<-
X[rdf:type->sw:AcademicStaff; sw:cooperateWith->Y[rdf:type->sw:AcademicStaff]].
On which projects do the phd students work that are supervised by a professor whith the email-adress "studer@aifb.uni-karlsruhe.de" ?
FORALL ProjID <- EXISTS PhdID, ResID
PhdID[rdf:type->sw:PhdStudent;sw:worksAtProject->ProjID;sw:supervisor->ResID]
and ResID[rdf:type->sw:FullProfessor;sw:email->"studer@aifb.uni-karlsruhe.de"].
Give me the organization that finances a project that deals with the research topic "ontology articulation" as well as all the person in this project that work in that topic?
FORALL OrgID, ProjID, MemID <-
OrgID[rdf:type->sw:Organization;sw:finances->ProjID]
and ProjID[rdf:type->sw:Project;sw:isAbout->"Ontology
Articulation"; sw:member->MemID].
Find me the name of any project that has members with the homepage 'http://www-db.stanford.edu/~stefan/' and and tell me who they work with
FORALL ProjID,MemID,OrgID<-
ProjID[rdf:type->sw:Project; sw:member->MemID]
and MemID[rdf:type->sw:AcademicStaff; sw:homepage->"http://www-db.stanford.edu/~stefan";affiliation->OrgID].
3. Task: Describe how you would expect these queries to be implemented. Identify the major DAML software components and sketch the control and data flow among them. Your solution may address some or all of the following topics query language, dynamic retrieval, crawling, cacheing, translation, inference, scalability, consistency, security). Consider how this could be accomplished if some of the DAML content was sensitive information stored on multiple WWW sites protected by passwords and/or certificates. You may or may not have access to all of the data.
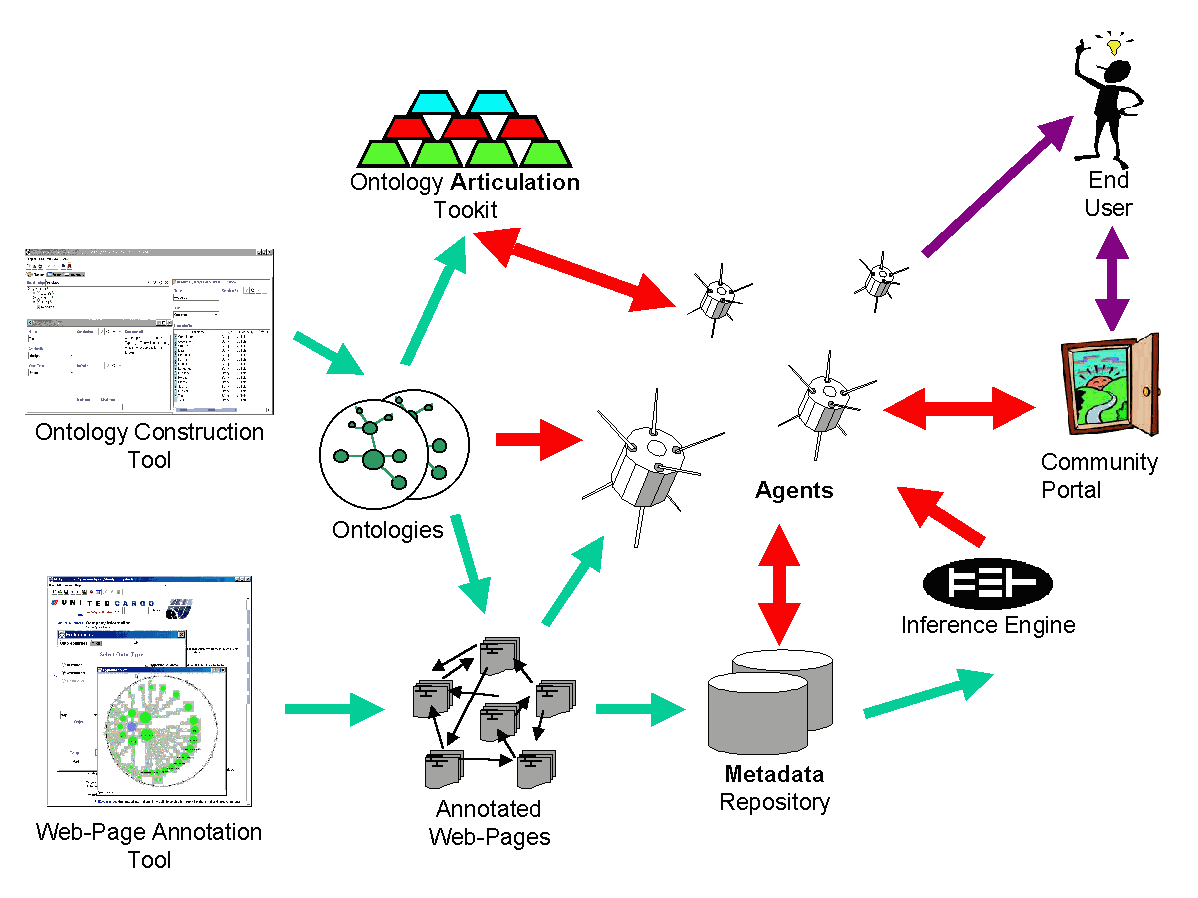
The overall agent infrastructure requires an information food chain: every part of the food chain provides information, which enables the existence of the next part. The food chain starts with the construction of an ontology, preferably with the OnTo-Agents Ontology Construction Tool. The ontology defines the terms that are possible to use for annotation information in webpages, using the DAML language. The proposed OnTo-Agents Webpage Annotation Tool has means to browse the ontology and to select appropriate terms of the ontology map to mark-up sections of a webpage. The webpage annotation process creates a set of annotated webpages, which are available to an OnTo-Agent to achieve its tasks. The OnTo-Agent itself needs several sub-components, specifically the OnTo-Agents Inference System for the evaluation of rules and queries and general inferences, the OnTo-Agents Ontology Articulation Toolkit for mediation among information obtained from different ontologies. The data in from the annotations can be used to construct additional websites: a Community Web Portal, that presents a community of interest to the outside word in a concise manner. And finally, information-seeking users can give specific retrieval tasks to an OnTo-Agent, or they can query a Community Web Portal for immediate access to the information.
The query processor itself needs to be scalable and to deal with millions, maybe billions of simple statements. Database technology provides this scalable infrastructure, but not for free: query optimizations have to be analyzed and implemented. Scalable retrieval technology should be based on well investigated deductive database technology, which provides special optimization strategies for typical queries. On top of the database technology it is necessary to implement a query language, that allows graph navigation in large RDF graphs and that supports special RDF features. The tradeoff between caching of data and retrieving and query time remains to be investigated. Especially the semantics of query answering with retrieval at runtime remains largely open.
4. Task: Extra Credit: Develop software to implement any or all of 3
W e have developed an RDF/DAML-Crawler
The specialized query and transformation language for RDF and DAML is under
development. The inference core will be based on 1) the Java core of SiLRI and
2) XSB
5. tool wishlist
8. discussion of lesson learnd and insights
|
By Stefan Decker, Siegfried Handschuh |