Value-added Middleware: Mediators
Pre-publication draft, subject to revision
Stanford University
March 1998
Abstract
As information systems become larger more functions can be assigned to middleware, avoiding problems associated with fat clients as well as with fat servers. We describe mediators, modules which occupy an intermediate layer. They perform functions as integrating domain-specific data from multiple sources, reducing data to an appropriate level, and restructuring the results into object-oriented structures. Their output is formulated for effective use by the clients. A major benefit of mediation is the scalability and long-term maintenance of the integrated information systems structure, due to the decoupling of servers and clients. Examples of current applications illustrate the technology and its effectiveness.
Crucial concepts are:
Value-added middleware services are domain-specific, providing a natural partitioning, which in turn enhances scalability and maintainability.
1. Introduction
As information systems become larger their complexity becomes a crucial concern. While client-server systems with many components can be rapidly assembled with current middleware technology [Kern:1994], their maintenance costs are high. By assigning sharable functionalities into services at the middleware layer, the high cost of adapting servers to increasing demands by client application can be mitigated, without forcing client applications to become convoluted as the customers' demands become broader and more pressing.
Many common functions could be shared among applications, but, as shown in Table 1, they are not conveniently assigned in the 2-layer client server model [Wiederhold:92C]. Placing them into an unsuitable architecture increases maintenance costs. As systems become larger the list of required functions and their information resources grows. Unfortunately, maintenance, often already 80% of the budget of an information systems department, grows even faster than the number of functions and components, since all these elements interact with each other [LientzS:80].
For instance, a new information function for a customer may not affect a client application greatly, but is likely to require additional server capabilities to provide the data. When a server is changed, all other client applications must be checked, and perhaps adapted to the server changes. Switching to the new version must be scheduled weeks or months in advance. In large operations many maintenance actions will arise in that interval, all to be installed at the scheduled timepoint. Any software manager is well aware of the risks and tensions that are part of a system upgrade, when dozens of perhaps minor, changes combine to create a major hassle [Wiederhold:95M].
We will show how the introduction of a intermediate layer permits isolation of maintenance tasks in Section 8.3; it allows rapid introduction of upgrades and keeping systems at a high level of performance. The next section will describe the value-added functionalities of the mediator design.
2. Sharable functions
In a 2-layer client-server architecture all functions must be assigned either to the server or to the client. The current debates on thin versus fat clients and servers illustrate that the alternatives are not clear, even though that some function assignment are obvious.
Selection of data is a function which is best performed at the server since one does not want to ship large amounts of unneeded data to the client. The effectiveness of the SELECT statement of SQL is evidence of that assignment; not many languages can make do with one verb for most of their functionality.
Interaction with the user is an obvious function for the client. Local response must be rapid and reliable. Adaptation to the wide variety of local devices is one aspect. Moving from displays and keyboards to voice output and gesture input requires local feedback. Maintaining such software variety in the server is also costly, even where technologies as Java provide uploading from server to client.
Open for discussion are functions as integration of data from multiple sources and transformation of server data to information that is effective for the client program. Most clients are best served by information in object-oriented form, which may integrate multiple heterogeneous sources [PapakonstantinouGW:95]. Table 1 illustrates the problems faced in a two-layer architecture.
|
Problems of |
INTEGRATION |
TRANSFORMATION |
|
at Servers |
A single server cannot effectively perform integration with data from other servers. The maintenance required to remain consistent with many other servers requires a level of knowledge and concern distinct from that required to do ones own job well. |
A server would have to understand and rapidly adapt to the needs of a variety of clients. Different client groups are likely to require different object configurations
|
|
at Clients |
Each client program has to maintain knowledge about multiple servers for integration. It is awkward to effectively share this knowledge with other clients.
|
Only retrieving raw data and then transforming it in the client again requires the acquisition of redundant data, and makes direct sharing of the functions with other clients impossible. |
Table 1: Problems of function assignment in a two-layer system.
3. Three layers in a large-scale system
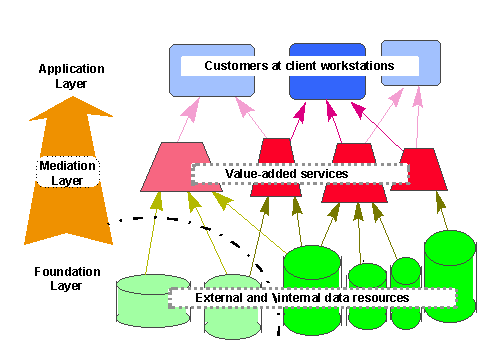
In the three-layer mediated model we distinguish serving resources, the client applications, and the intermediary, value-adding mediators, as sketched in Figure 1. We discuss first the roles of clients and servers in this architecture.
Figure 1. Mediators for external and internal resources
In a large system there will be many servers, providing data from local and from external resources. Any external, and many internal systems which provide data are developed and maintained autonomously. The motivating applications for databases tend to be transactional (OLTP) operations, as inventory control, payroll, production control, etc. Eventually the data they contain become important to supply information for high-level client application, serving planning and decision-making. In the long-range these information applications increase in importance, but still should not impose constraints on day-to-day operations [WiederholdG:97].
The number of potential client applications also increases with time more rapidly than OLTP applications, since management needs change frequently as one issue is dealt with and the next one arises [SilberschatzSU:91]. Client-sever architectures are attractive in this arena, since they can be designed and established rapidly, with minimal impact on the server. However, if many of them have to be maintained, considerable maintenance complexity ensues.
Client information service applications are typically designed independently, and later than the base OLTP applications. For instance, planning support must be synchronized with management objectives, which change frequently. Their implementation has to rely on existing sources, since it is rare that sufficient time is available to build planning systems and their data collection from scratch. Complementary sources of information for decision making are external, obtainable from financial information systems, digital libraries, geographic information systems, and simulations.
Dealing with many, diverse, and heterogeneous sources soon overwhelms high-level client applications with excessive emphasis on irrelevant, but crucial details. Especially web access is difficult to manage [HammerG+:97]. Mediators provide intermediary services, linking data resources and application programs. Their function is to provide integrated information, without the need to integrate the data resources themselves. Specifically, the tasks required to carry out these functions are comprised of
Overall, mediation adds value by converting data to information. Figure 2 depicts some of the tasks in symbolic form in. One should note that in value-added mediation more effort is devoted to processing the results of the retrievals than to access. Locating and gathering the data is a prerequisite, but does not provide the desired end result: information in a format that can be directly and effectively used by the client applications. Value-added services in a mediator include active integration of data, dealing with incomplete responses [ChuQ:94], and further processing to increase the information content.
A summary of the needed processing is provided in Sections 3.2 and 3.3, specifics are given in Section 5, and its value is the topic of Section 8.
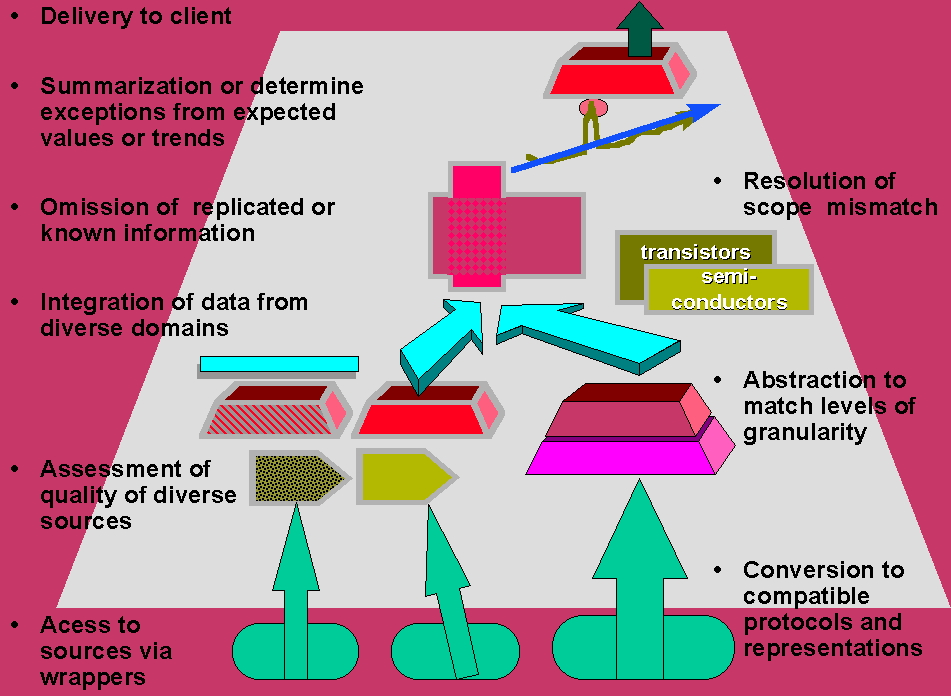
Figure 2. Services in a Mediator
3.1 Access to remote services
Accessing remote servers, especially if they have been developed autonomously has been a long-standing problem. Many types of heterogeneity will appear in such settings, as differences in hardware, operating systems, database systems, database schemas, and scope. We cite some partial solutions that have been described in Table 2, often in this magazine. Concepts from these solutions are incorporated in mediation, but the intent of mediation is to deal explicitly with maintaining autonomy of servers.
|
multi-database systems
|
allowing queries to address more than one independent source database |
|
federated databases
|
integrated schemas to support joins over multiple, consistent databases |
|
wrappers
|
server front-end software to provide SQL access to non-database files or legacy databases |
|
knobots
|
Software agents search for relevant data through multiple databases or the web |
|
webcrawlers
|
software used to retrieve data from the web for incorporation in local databases |
Table 2. Precursors to mediated systems
3.2 Integration
It is rare that data which were autonomously developed can be integrated by simply executing joins over their attributes. More often integration requires
1. Resolution of scope mismatches. Scope mismatch occurs when the records kept in a table from source A do not cover the same set of items collected in source B; for instance,
Purchases versus Inventory lists. Some purchased items are not inventoried.
2. Abstraction to bring material to matching levels of granularity for integration; for instance:
Employee hours versus Project labor budgets.
3. Omission of replicated information; for instance:
Employee addresses` exist in both sources, but in differing form.
4. Interpolation or extrapolation to match differences in temporal data; for instance:
Labor records are weekly, but budgets are monthly.
While we can develop rules and write programs to deal with these issues, placing the responsibility for coherence on client programs is a heavy burden, and is best shared through intermediate services [PapakonstantinouAG:96].
3. 3 Methods to increase the information content
As the volume of data is increasing through better access and more integration the customer becomes overwhelmed, and is actually less effective due to information overload. Information should be novel, and reduce uncertainty in decision-making [Shannon:48]. We list here processing tasks that can reduce the overload. Some of them will be presented in more detail in Section 6.
1. Reduction of historical data to limited snapshots
2. Assessment of quality of material from diverse sources
3. Pruning of data ranked low in quality or relevance
4. Omission of information already known according to the customer model
5. Statistical summarization into higher level categories, as relevant to the customer
6. Generalization and broadening of search to satisfy query expectations
7. Reporting exceptions from expected values or trends
8. Triggering of actions due to exceptions from expected values or trends
9. Adaptation to the bandwidth and media capabilities of the customer
10. Sending the information and meta-information to the customer application
These services are not independent. What combinations will be needed depends on the domain that the mediator serves. For instance, for financial services matching levels and dealing with temporal differences is often important.
An example of a combination of processing steps required includes:
1. Conversion of currency according to rates prevailing in the period
< P>2. Adjusting for inflation using cost-of-living indexes and standard projections3. Matching weekly, monthly, and quarterly reporting periods
4. Adjusting for differences in corporate financial years to a common calendar
A mediator can provide such services for many clients. Placing them into mediator increases the consistency of analytical results among those clients. For instance, if distinct analysis differ in their expectation of inflation rates, comparisons become futile: "Inconsistent valuations are worse than none" [SharpeK:94].
These, and many similar tasks are now carried out redundantly in most applications. Even if the code is shared, loss of control over parameters allows promoters to make their favored alternatives look best. When these tasks are performed in a two-layer, client- server, architecture they are either built into customer applications or database services. When built into applications the applications have difficulties keeping up with the variety and change in resources. If servers are to provide such derived results for many clients much complexity ensues, especially if related servers must be accessed for complementary information, say the current conversion rates.
3.4 Keeping mediators simple
A service that a mediator should not have to provide is the actual presentation. The clients' computers today are sufficiently powerful to convert information into user-friendly form. The code needed to deal with the variety of graphical user interface (GUI) devices, as windows, pop-up, roll-down, scroll, cut-and-paste, drag-and-drop, data visualization, animation, speech, and so on, is often particular to the device, and not to the information content [Wiederhold:93].
If the client contains a web-browser, which provides a basic set of representation primitives, the mediator may create and ship information formatted in HTML. Receiving webpages will not be helpful if some client applications need to further processing with local data, or need to combine information from more than one mediator <as described in Section 7.
Mediation is hence simplified by delegating the complexities of the customer interface to the application program. Generalizing such services often occupies more than 70% of servers of thin clients. Now the mediators and the invoking applications only need a machine-friendly application program interface (API).
4. Interfaces
Mediation is primarily an architectural concept. The precise implementation of the mediating software is less important than its ability to perform its functions in the context of the overall system.
Since the mediator architecture is conceptually comprised of three layers, as shown in Figure 3, there will be two major interfaces:
A. Mediators to applications
B. Base resources to mediation
Practical, large-scale systems will also have intermediate interfaces, since within the mediation layer a number of sublayers can exist as well. For these the technologies of type A. are also appropriate.
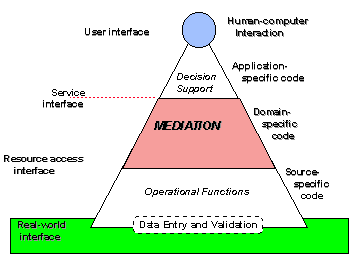
Figure 3. The Mediation Layer and its interfaces
Much of the effort in moving to sharable mediator architecture involves the recognition of interface standards, so that configurations, i.e., instances of the architecture, can be rapidly assembled. There is a strong linkage here to concepts as virtual enterprises; mediation provides the required openness in the architecture.
For the base interface (B.) the many tools that are becoming available to serve the two-layer server-client model are appropriate, as distributed and augmented SQL, OQL, ODBC, and other interfaces for object-oriented access, as CORBA [VassalosP:97]. Older, legacy applications may have to be wrapped [HammerB+:97]. Complex data structured may be transferred using the Abstract Syntax Notation of the ASN-1 standard. (ISO IEC 8824&8825).
At the application layer (A.) the interfaces need greater capabilities. We mentioned earlier HTML for thin clients, and if data is sufficiently reduced, JAVA can be effective. CORBA still has a role here, as do the other object model standards. For specific domains, specialized standards exist, as PDES objects for engineering, may be appropriate. The requirement is, of course, that the sender and the receiver agree on the chosen representation. They also should agree on the vocabulary and its structure, i.e., the ontology. For this purpose a Knowledge-Query-and-Manipulation-Language (KQML) has been developed with support from DARPA, which provides further desirable features, but some of them are now appearing in CORBA and its successors as well.
5. Reducing Information Overload
To provide the most important value-added mediation service, reducing information overload, requires substantial processing and a model of the customer’s requirements. Since an object configuration provides such a model, performing a transformation into an object format is often part of the processing at this point [BarsalouW:90].
5.1 Summarization
Summarization provides aggregated data, following the hierarchy established by the object model. In systems without mediators summarization is specified by the client, and, to the extent that SQL functions are available, executed by the server. However, SQL does not provide aggregate functions for variance or standard deviation, needed to check if averages are based on simple distributions. Even moderately complex summarizations must then be done in the client. Often the source data must be filtered to delete anomalies, perform conversions if data come from multiple countries, and the like.
In current practice, much of the computation for summarization is performed by moving data from databases into spreadsheets, and performed by staff outside of the database services. Such staff explicitly programs their view of the customer's model. For example, cost data collected in a factory are at a level of detail which records the activity of every worker and every machine with respect to every task. For the payroll domain the worker's efforts are aggregated to daily hours, and then processed with data which determine overtime rates, and then further aggregated to weekly totals, which determine pay checks. At the pay level benefits are added, taxes are computed, and contributions are withheld.
The same source data from the factory floor can be aggregated according to a different customer model to arrive at costs per product, and to this aggregation the allocation of product development costs is added to arrive at the base costs which eventually can determine sales prices and profits.
5.2 Exception seeking
An alternate, even more effective, abstraction is created by seeking for exceptions. In this mode only results that differ significantly from the customer's expectation are presented, for instance, abnormal clinical findings or an unexpected drop in sales for a product line. The need for a customer model is obvious here. A change in a patients weight by 10% over a short time is typically a cause for concern; putting absolute limits on weights would lead to useless exceptions, even if patients were categorized by age, height, and gender.
Many business decisions are motivated by changes in customer demand. Simple tabulations do not tell the full story. Sale amounts are affected by exchange rates and promotions. Factory sales are buffered by inventories. Many products are affected by the weather and regional preferences. Only when these have been taken into account by specialists is it useful to use the information for production planning and investment decisions.
5.3 Reduction of historical information
Increasingly, systems collect historical data. Such data is first of all reduced by aggregating it to intervals which produce an adequate overview, say by months or quarters. For sales data, further corrections can be made by normalizing data to expected annual cycles.
A further reduction can be made be reducing the data points to a slope, by giving the rate of increase, or to a mean combined with a variance over the preceding period.
5.4 Benefits
The use of mediators to provide such summarization services provides several benefits.
6. Domain-specific Mediators
Maintenance concerns alone make it infeasible to have the functions of integration and abstractions for all sources and all applications concentrated in a single piece of software, managed by a single organization. A reasonable guideline for partitioning the mediation tasks is by domain: a mediator should be maintainable by a single coherent group. Such a group will use terms and structure object models consistently. A dual of this rule is clear, maintenance by committee is a disaster, since a committee's objective is to achieve a compromise, rather than precision. We see that today that companies that build mediators also specialize on domains, although we hope that the tools they develop will often address broader communities as well.
Having multiple object models does raise a problem in updating when the object contains only a portion, namely a database view, of the source relations [Wiederhold:86]. The objects represent essentially a view, and view updating without the broader knowledge of an expert, as the database administrator, is ambiguous, and hence risky and often disallowed. However, such expertise can be brought into the mediator. In the approach we have developed all possible updated ambiguities are enumerated and ranked when the mediating transformation is defined. Hence, a byproduct of having mediation is a practical solution to the view-update problem, without having to involve customers in issues beyond their concern.
We present mediation as the principal means to resolve problems of semantic interoperation. However, mediation will be needed in many topics, and we cannot expect that single mediator can cover all topics of interest to any application. We can expect even less that a single group of individuals can develop and maintain such a general mediator. We also expect that many client applications need to combine more than one topic, and hence need support from multiple mediators, as shown in the example of Figure 4. Different applications will use different configuration of mediators. For instance, a production planner needs production cost estimates and product demand information. The sales manager needs the demand information, perhaps at a lower level of granularity, and inventory data.
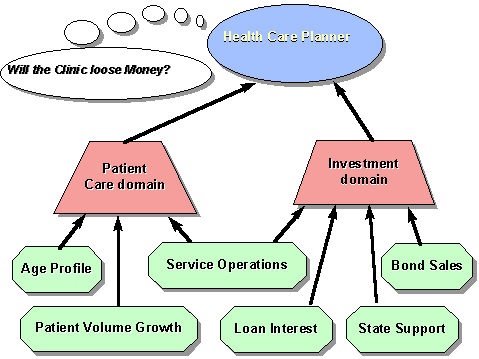
Figure 4. Example of linking Resource, Mediators, and Applications.
7. Using Multiple Mediators
We kept mediators simple by restricting each of them to single, coherent domain. Advanced application, specifically in decision support, must often resolve conflicts among disparate domains. For instance, investment decisions involve financial and production information, which is produced using different metrics. Integration of incomensurate information is best done at a higher level than that occupied by domain specialists,: i.e., in a client or a higher level mediator.
Having a hierarchical customer model driving a mediation process does not inhibit client applications from integrating results from multiple mediators, and accommodating dissimilar domains. Such a high-level integration will be pragmatic, since it is difficult to apply formal comparable metrics in dissimilar domains. For instance, while employee competence and cost may be combined in an analysis for personnel productivity, the same comparison will not hold rating amateur sports teams. Figure 3 illustrates the two levels of integration.
The need for conceptual clarity also supports the use of hierarchies within mediators. Simplicity is essential, as for any software you want to work reliably. A mediating module carries out tasks to serve a customer, and a desirable aspect of such a computer- based servant is that it has a model to which permits the customer to understand its capabilities. Making the model used by the mediator visible to the customer, perhaps through a web-based description, will help the client to use it completely and effectively.
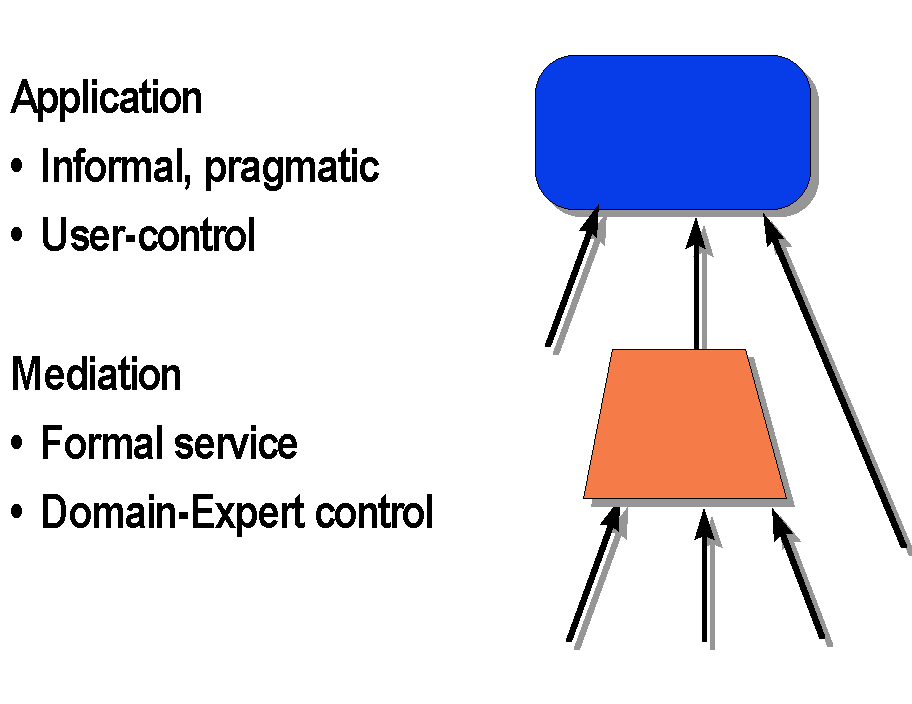
Figure 5. Integration at Two Levels
To support higher level integration and processing mediators should provide the machine-friendly interfaces discussed in Section 3.4.
8. Value
To warrant implementation of a mediating service as a distinct module there must be enough added value to overcome the cost of adding a layer and its interfaces into the information processing flow. But the costs and benefits to be considered are only partially related to performance. Having identifiable and maintainable service modules provides significant long-term management benefits [Wiederhold:97]. Some of these services will be best provided by independent enterprises over the networks, or their programs can be leased to provide these services at customer sites, as detailed for digital libraries [Wiederhold:95A].
8.1 Value added by increasing the density of information
A major task for an effective mediation service is the reduction of data volume to be shipped to users' application, while maintaining its information content. More information embedded in less data increase the information density. Having a high information density deals with the complaint that customers voice now: that there is information overload. Reduction of transmission to the customer's workstation also reduces communication delays and costs. The principal tool for data reduction is abstraction, either by summarization or by exception seeking. Both functions depend on having a simple, hierarchical model of the customer's needs [Wiederhold:92I].
8.2 Value added by transforming data to object structures
Making information relevant to clients often means transforming them into an object- oriented format. Object technology enables applications to use an infrastructure which aggregates detail into meaningful units in many important domains. Internally, objects have hierarchical linkages since the class definitions that control them are based on hierarchies. Objects provide a valid customer model, even when the real-world is more complex.
A customer model focuses on a task set and a domain of interest. The same user may be assume a different customer role at other times, and is then represented by a distinct model. These customer models are hierarchical. Resorting to informal reasoning we consider that people, when faced with complex tasks, categorize the processes and objects to be dealt with, so that they can apply a divide-and-conquer paradigm. Good categorizations are taxonomies with two attributes: disjointness: no object belongs to more than one category, and completeness: all objects can be classified.
In database technology, a view relation, defined by a single SQL view expression, also creates a hierarchy. A view relation is no longer in normalized form. Each join in the view expression defines a relationship. The attribute named by WHERE clause of the join along a relationship defines the higher level. Since SQL views have been adequate for applications, using hierarchical models in mediation follows a well-accepted path.
The acceptance by customers of object models, which are also hierarchical in nature, argues for the hypotheses that customer models can be hierarchical, and hence manageable within this paradigm. A major value-added contribution of mediation is then the creation of object structures out of the complex and interconnected world of real data. A domain expert will be needed to manage the mediators transformation programs. It that expert that provides the value, and should be reimbursed for it.
However, defining single fixed, large-scale object structures for a variety of purposes has required great pain and compromises [AppelbeEa:95]. The assumption that one hierarchical viewpoint is right for all occasions is demonstrably false: the object model of an inventory of assemblies differs for the purchase agent acquiring the parts from the suppliers and the factory assembling them. Very large hierarchical objects, say, having 200 elements, nearly always create conflicts of viewpoints. Forcing unsuitable and overloaded representations onto the clients processing programs increases the cost of finding and executing solutions; it is well known in mathematics that finding the right representation for a problem is 80% of the effort, and the same holds true in computing. Mediators work best if they create specific, well-defined object representations.
Multiple mediators can generate alternate object configurations from the same base data without having redundant persistent data, and the inconsistency problems that arise in that case.
8.3 Value added by Maintenance
Mediation adds value to the data by applying the knowledge of the expert who has created the mediator. Mediators should also be maintained by those experts, so that the quality of the functions of a mediator remain effective in a constantly changing world [Arthur:88]. As soon as an improved mediator is developed it can be advertised over the network, both to existing subscribers as well as to potential new clients. A poorly maintained mediator will lose value over time, and be a candidate for replacement by a competitor. Existing customers can continue to use the old mediator version, and not be disturbed until they decide that their application needs the upgrade. This flexibility is crucial, since now upgrades are not constrained by the effect on the existing community of customers. The maintainer will, of course, try to keep the number of versions of a mediator service modest. The charges for old mediators may increase, to encourage applications that depend on old versions to upgrade.
9. Status
Mediator modules provide intermediary services in information systems, linking data resources and application programs. Early solutions that led to the concept of mediation were either constructed to support specific applications, or implemented as extended services from databases [RischW:91]. Currently mediators are being built by innovative companies that are gaining experience and developing reusable tools for their internal use.
No mediated system exists today that performs the full set of tasks described above. We do however have partial examples. Creating objects from relations is provided by commercial implementation provided by Persistence Software to Sunsoft and other system implementors [KellerJA:93]. If that technology can be applied to mediator generation a considerable increase in scale and significance of that technology may ensue, several projects are now working on such a scale-up [Reinwald+:94].
A number of contractors have now the capability to build the required application interfaces and implement the architecture. The number of platforms and languages varies, and there is some discussion on style, as preferring fat versus thin mediators. They interact with their customers to acquire domain knowledge. As more implementation enter practice the infrastructure grows, and we expect that mediators can be installed rapidly and be maintained by their owners
We list some of the companies now active in the area, since they are still relatively unknown. There are of course many larger companies that are also building systems for their own use.
Suppliers of Mediation Technology:
-------------------------------------------------
Name: BEA systems
Town: Sunnyvale CA
Specialty: large-scale infrastructure (TUXEDO platform; MessageQ messaging)
Contact: Bill Coleman
coleman@BEAsys.com------------------------------
Name: Constellar
Town: Redwood Shores CA
Web:
http://www.Constellar.com/Speciality: rule-based warehouse population
Contact:
info@constellar.com---------------------------------------------------------
Name: Epistemics
Town: Palo Alto CA
Web:
http://www.epistemics.com/Speciality: Mediator software, resource scheduling
Contact: Arthur Keller
info@epistemics.com--------------------------
Name: FastXchange (spinoff from ISI)
Town: Marina del Rey, CA 90292
Web:
http://www.FASTXchange.com/Speciality: procurement
Contact: Anna-Lena Neches
info@fastxchange.com--------------------------
Name: Genelogic
Town: Berkely CA
Web:
http://www.genelogic.com/bioinform.htmSpeciality: genomics information in object form
Contact: Victor Markowitz
victor@genelogic.com-----------------------------------
Name: Global InfoTek, Inc.
Town: Vienna, VA. 22180
Web:
http://www.globalinfotek.comSpecialty: mediation and Java-based ad hoc query and visualization tools.
Contact: Ray Emami
gemami@pluto.globalinfotek.com-------------------------------------------
Name: IBrain Software
Town: Palo Alto
Web:
http://www.ibrain.comSpecialty: integration and ranking of financial information, mediator software
Current Specialty: Financial services.
Contact: Vishal Sikka
vishal@ibrain.com------------------------------
Name: I-Kinetics Inc,
Town: Cambridge MA
Web:
http://www.i-kinetics.com/Specialty: scalable acess methods
Contact: Bruce Cottman
bruce.cottman@i-kinetics.com------------------------
Name: ISI
Town: Marina Del Ray, CA 90292
Web:
http://www.isi.eduSpecialty: research, system engineering
Contact: Ygal Arens
arens@isi.edu----------------------
Name: ISX
Town: Westlake Village CA
Web:
http://www.isx.comSpeciality: intelligence systems, planning and logistics
Contact: Nancy Lehrer
Nlehrer@isx.com------------------------------------------
Name: Junglee
Town: Sunnyvale, CA
Web:
http://www.junglee.com/Speciality: web source integration and filtering for shopping, job placement, etc., used by Yahoo a.o.
Contact: Anand Rajaraman
anand@junglee.com----------------------
Name: K2 Informatics, Inc.
Town: Bryn Mawr, PA 19010
Specialty: genomic information
Contact: Karen J. Giroux
71072.234@compuserve.com-------------------------------------
Name: Lockheed-Martin Idaho Technologies
Town: Idaho Falls, ID
Web: http://id.inel.gov/idim;
http://id.inel.gov/merlinSpecialty: environmental, chemical data
Contact: Lynn Dean
lad@inel.gov-----------------------------------
Name: Lockheed Martin C2 Integration Systems
Town: Frazer, PA 19355-180
Web:
http://www.paoli.atm.lmco.com/kqmlSpeciality: systems engineering, communication (KQML) for government
Contact: Robin McEntire
Robin.A.McEntire@lmco.com-----------------------------------
Name: MCC
Town: Austin TX
Web:
http://www.mcc.com/projects/infosleuth2/Specialty: mediating agent research for consortium members
Contact: Marek Rusinkiewicz
Marek@mcc.com-------------------------------------
Name: Persistence Software
Town: San Mateo CA
Web:
http://www.persistence.comSpecialty: relation to object transformation
Contact:
keene@persistence.com------------------------------------------
Name: Socratix
Town: Palo Alto CA
Web:
www.socratix.comSpecialty: clinical and biological information
Contact: Russ Altman
altman@smi.stanford.edu----------------------------------------
Name: Tesserae Information Systems
Town: San Jose, CA 95113
Web:
http://tesserae.com/Speciality: electronic commerce
Contact: Narinder Singh
singh@tesserae.com10. Implementation
A number of applications have been developed using mediator technology [Lehrer:94]. We show a listing of companies providing aspects of mediation technology. Early applications were in military intelligence, since that is a domain where customers can impose no control over many sources. Subsequent applications have focused on manufacturing, where design and prototype production data have been combined [Wiederhold:96]. A specific application has been the selection and validation of gimbals for antenna positioning on spacecraft at Lockheed Space Systems. An interesting spinoff project is in the collection and integration of satellite data for land-use planning. Other areas being developed now are in healthcare management and plant safety and environmental cleanup, as described in the INEEL sidebar.
The implementation of mediators varies greatly. Workstations are the favored platform, often using UNIX. Many current mediators have been coded in the C and C++ languages. Where knowledge-based processing is crucial, mediators have been programmed in languages as LISP or with CLIPS, a C-compatible rule language [MalufWLP:97]. If optimization is crucial to processing, the mediators may depend on packages written in FORTRAN. For the customer the implementation should not be the issue, but for maintenance making a wise choice is crucial. Such early development handcrafted domain specific applications.
Some companies now focus on providing the framework for mediators. For instance, IBrain's core technology is a single framework for querying and analyzing information of multiple types, from multiple places, using multiple analytical methodologies. The technology allows integration of heterogeneous information and analyses as text search and information retrieval for unstructured text data, data analysis and OLAP type analyses for structured database data, collaborative filtering for qualitative data, and prediction and mining type techniques for quantitative data. The domain focus has been on finance, but the expectation is that their technology will be applicable also in industries as healthcare, pharmaceuticals, manufacturing, and enterprise management.
Combining domain-specific applications with generalizable technology provides a way to show new customers the benefit of mediation technology. At INEEL the application development preceded the generalization of the software. Similarly, Junglee first provided access to positions advertised on the World-Wide Web. Now their Virtual Database technology enables rapid creation of mediators using off-the-shelf tools. Junglee has now applied this technology also to Web Commerce. Junglee's customers and partners in these markets include six of the top seven newspaper media companies, new media companies like Yahoo!, and established publishers like Ziff Davis.
Merlin - Transforming Legacy Data into Meaningful Information
Merlin is a software developers' tool being developed and tested at the Idaho National Engineering and Environmental Laboratory (INEEL) by Lockheed Martin Idaho Technologies Company. It is based on a combination of mediator and expert system technologies. Merlin ties together several disparate computerized data sources and makes them function as a cohesive whole. Merlin turns several databases into one virtual database, eliminating the need for each client application to perform its own data integration.
Several client applications that need the same data may access and integrate the data differently, coming up with reports that conflict even though the same basic data were used. This inconsistent data interpretation can lead to incomplete information, inefficient decision-making, and, in the case of reports to regulators, fines.
Merlin, a set of software modules that form an active layer between client applications and data sources, can filter the inconsistencies. Within this layer, sometimes called the semantic layer or information catalog, data are "described" in context. Merlin can be provided with knowledge about the various data sources. Examples of such knowledge include business rules and corporate knowledge that affect how the data should be interpreted and ways in which data from various sources may or may not interrelate. Distributing this knowledge to every client application is likely to be cost-prohibitive and logistically impossible. Using the Merlin modules can be a cost-effective, workable solution. Applying this knowledge, Merlin gives consistent answers regardless of who asks the question or how the question is asked.
It is important to note that Merlin is not bound to any single client application nor to any specific data sources. Merlin can be "taught" to understand, select, merge, manipulate, and integrate data, giving every client application synthesized, consistent information. Merlin's software components utilize a combination of mediator and expert system technologies to assure their adaptability for use by various disciplines. These software components accept domain-specific details (e.g., schema, mappings, expert system rules) as data from a knowledge base. This enables the same software to be used for a variety of domains and client applications with no source code modifications or recompilations required.
In a data management project at the INEEL, completed in 1997, Merlin integrated environmental sampling data from an existing Oracle database and two existing FoxPro databases. This project demonstrated that data from these databases could be seamlessly integrated and easily accessed. Because of its ability to work with existing data structures, Merlin can be cost-effective even if database upgrades are planned. For instance, upgrading a data system could cost millions of dollars. How do you keep the data available during upgrades? For much less, Merlin can tie the system parts together while the upgrades are phased in, making it possible to spread the cost of the upgrade over time. Merlin can also make it possible to access the data during the upgrade, tying together the old and the new as the upgrade progresses.
Merlin can be a cost saver after upgrades are completed. Let's say you have several databases that contain historical data that you want to preserve and be able to access but that may not justify the cost of reprogramming. Merlin can tie the existing historical databases into the upgrade. Information is an organization's lifeblood; the quality of that information has far-reaching effects. Managing information resources takes an ever-increasing portion of an organization's budget. A technology that makes cost-effective use of that portion is a valuable asset. With Merlin, Lockheed Martin Idaho Technologies Company is developing such technology.
For additional information contact:
Technical: Lynn A. Dean lad@inel.gov
Business: Scott H. Harris shh@inel.gov
11. Conclusion
Client-server architecture has allowed the rapid implementation of a variety of information systems. Providing added value in those systems requires in each instance services of specialist domain model experts and programmers for the implementation. Maintenance of these systems requires continued collaboration of clients, servers and experts, and puts limits on the number of clients and servers that can collaborate.
Mediation is an architecture intended promote reuse and scalability, so that sources from many domains can contribute services and information to the end-user applications. The layered structure actually adopts for information structuring the domain management strategy used by the Internet distributed naming conventions. Software technologies have been hard to scale when domains grew large or became diverse.
Mediators represent responsible, predictable and stable services. To warrant the use of mediators, there should be significant value-added processing. Data reduction, exception search, dealing with uncertainty among heterogeneous resources, and ranking of results are examples. The owner of the mediator assumes responsibility for the correctness of such processing. The partitioning into domains creates a desirable autonomy to reduce the cost of maintenance.
In mediators the management of its operation and function is the responsibility of a human owner. The mediator program, as directed by its owner, tries to
Mediator owners take on the responsibility, authority, and should be reimbursed for the value-added information services being provided.
The focus on maintenance distinguishes the mediated approach from many other proposals, which attempt to design optimal systems. In large systems the major costs are due to integration and maintenance, rather than in achieving initial functionality and optimality. Integration in mediation can proceed at multiple levels of abstraction, avoiding the centralization that hinders progress in data exploitation of data from diverse sources.
References
[
[Arthur:88] Lowell Jay Arthur: Software Evolution: The Software Maintenance Challenge; Wiley, 1988.
[BarsalouW:90] T. Barsalou and G. Wiederhold: "Complex Objects For Relational Databases''; Computer Aided Design, Vol. 22 No. 8, Buttersworth, Great Britain, October 1990.
[BarsalouSKW:91] T.Barsalou, N.Siambela, A.Keller, and G.Wiederhold: http://www-db.stanford.edu/pub/keller/1991/penguin-sigmod91.ps
``Updating Relational Databases through Object-Based Views''; ACM SIGMOD Conf. on the Management of Data, Boulder CO, May 1991.
[Basili:90] Victor Basili: "Viewing Maintenance as Reuse-Oriented Software Development"; IEEE Software, Vol.7 No.1, Jan. 1990, pp.19-25.
[ChuQ:94] W.W. Chu and Q. Chen: ``A Structured Approach for Cooperative Query Answering"; IEEE Transactions on Knowledge and Data Engineering, Vol.6 No.5, October 1994.
[HammerB+:97] J. Hammer, M. Breunig, H. Garcia-Molina, S. Nestorov, V. Vassalos, R. Yerneni: "Template-Based Wrappers in the TSIMMIS System"; ACM SIGMOD 26, May, 1997.
[HammerG+:97] J. Hammer, H. Garcia-Molina, J. Cho, R. Aranha, and A. Crespo: "Extracting Semistructured Information from the Web"; Proc. Workshop on Management of Semistructured Data, Tucson, Arizona, May 1997.
[KellerJA:93] A.M. Keller, R. Jensen, and S. Agarwal: "Persistence Software: Bridging Object-Oriented Programming and Relational Databases"; ACM SIGMOD, International Conference on Management of Data, May 1993.
[Kern:1994] Harris Kern: Right-sizing the New Enterprise; Sunsoft/Prentice-Hall 1994.
[Lehrer:94] Nancy Lehrer (ed.): Summary of I3 Projects; http://isx.com/pub/I3
[LientzS:80] B.P. Lientz and E.B. Swanson: <i>Software Maintenance Management</i>; Addison-Wesley, 1980.
[PapakonstantinouGW:95] Y. Papakonstantinou, H. Garcia-Molina and J. Widom: "Object Exchange Across Heterogeneous Information Sources"; IEEE International Conference on Data Engineering, pp. 251-260, Taipei, Taiwan, March 1995.
[PapakonstantinouAG:96] Y. Papakonstantinou, S. Abiteboul, H. Garcia-Molina. "Object Fusion in Mediator Systems"; VLDB 26, Morgan Kaufman, 1996.
[MalufWLP:97] David A. Maluf, Gio Wiederhold, Ted Linden, and Priya Panchapagesan: http://www-db.stanford.edu/~maluf/postscript/crosstalk.ps
"Mediation to Implement Feedback in Training"; CrossTalk: Journal of Defense Software Engineering, Software Technology Support Center, Department of Defense, August 1997.
[RischW:91] Risch, Tore and Gio Wiederhold: "Building Adaptive Applications using Active Mediators"; DEXA 91 (Database and Expert Systems Applications, Berlin, Germany, August 1991, D. Karagiannis (ed.), Springer-Verlag.
[Reinwald+:94] B. Reinwald, S. Dessloch, M. Carey, T. Lehman, H. Pirahesh and V. Srinivasan: ``Making Real Data Persistent: Initial Experiences with SMRC''; Proc. Int'l Workshop on Persistent Object System, Tarascon, France, pp.194--208, Sept.1994.
[Shannon:48] C.E.~Shannon and W.~Weaver: The Mathematical Theory of Computation;1948, reprinted by The Un.Illinois Press, 1962.
[SharpeK:94] Paul Sharpe and Tom Keelin: "How SmithKline-Beecham makes Better Resource Allocations Decisions"; Harvard Business Review, March-April 1998, pages 45-57.
[SilberschatzSU:91] A. Silberschatz, Michael Stonebraker, and J. Ullman (eds): http://www-db.stanford.edu/pub/papers/lagii.ps"Database Systems: Achievements and Opportunities"; Comm. Of the ACM, Vol.34 No.10, Oct. 1991, pages 110-120.
[VassalosP:97] V. Vassalos , Y. Papakonstantinou: "Describing and Using Query Capabilities of Heterogeneous Sources"; VLDB 27, Morgan-Kaufmann, 1997.
[Wiederhold:86] Gio Wiederhold: http://www-db.stanford.edu/pub/gio/1986/vod.ps``Views, Objects, and Databases''; IEEE Computer, Vol.19 No.12, December 1986, Pages 37--44.
[Wiederhold:92C] Gio Wiederhold: http://www-db.stanford.edu/pub/gio/1992/afis.ps"Mediators in the Architecture of Future Information Systems''; IEEE Computer, Vol.25 No.3, March 1992, pp.38-49; reprinted in Michael Huhns and Munindar Singh: Readings in Agents; Morgan Kaufmann, October, 1997, pp.185-196.
[Wiederhold:92I] Gio Wiederhold: http://www-db.stanford.edu/pub/gio/1991/roai.ps``The Roles of Artificial Intelligence in Information Systems"; Journal of Intelligent Information Systems; Vol.11 No.1, 1992, pages 35--56.
[Wiederhold:93] Wiederhold, Gio: "Intelligent Integration of Information"; ACM-SIGMOD 93, Washington DC, May 1993, pages 434-437.
[WiederholdG:97] Gio Wiederhold and Michael Genesereth: http://www-db.stanford.edu/pub/gio/1995/Expert.ps"The Conceptual Basis for Mediation Services"; IEEE Expert, Vol.12 No.5, Sep-Oct 1997, pages 38-47.
[Wiederhold:95A] Gio Wiederhold: http://www-db.stanford.edu/pub/gio/1995/acmfinal.ps"Digital Libraries, and Productivity''; Comm. of the ACM, April 1995.
[Wiederhold:95M] Wiederhold, Gio: http://www-db.stanford.edu/pub/gio/1995/er.ps"Modeling and System Maintenance"; in Michael P. Papazoglou (ed.): OOER'95: Object-Oriented and Entity Relationship Modelling; Springer Lecture Notes in Computer Science, Vol. 1021, pages 1-20.
[Wiederhold:96] Wiederhold, Gio (editor): http://www-db.stanford.edu/pub/gio/1996/I3book.html Intelligent Integration of Information; Kluwer Academic Publishers, Boston MA, July 1996.
[Wiederhold:97] Wiederhold, Gio: http://www-db.stanford.edu/pub/gio/1995/DS6CH.ps"Value-added Mediation in Large-Scale Information Systems"; in Robert Meersman and Leo Mark(ed): Database Application Semantics, Chapman and Hall, 1997, pages 34-56