Augmenting Information Systems with Access to Predictive Tools
Gio Wiederhold and Rushan Jiang
Stanford University
Computer Science Department.
Gates Computer Science Building 4A
Stanford CA 94305-9040
650 725-8363 fax 725-2588
<gio, jiang@db.stanford.edu>
Abstract
We report on a prototype system that provides access to computational tools that predict future states of the world. We also discuss its interoperation with SQL accessed resources which will augment the decision-making support capabilities of information systems. The central component is a new interface language, SimQL, which mirrors the functionality of SQL, but delivers information projecting future states, obtained from a variety of simulations.
Simulations to be wrapped for SimQL access include spreadsheets, business simulations, planning models, as well as large remote continuous simulations, as used for weather forecasting. Results reported through SimQL are paired data elements, the expected value and its certainty. SimQL is intended to be used within information systems that cover data from the past into the future, and support the assessment of the effects of alternate decisions, so that multiple future courses can be compared. Placing results of simulations into a consistent framework with databases and web-based information, avoids the system inconsistencies that decision-makers face today.
The long-range motivating vision is that an interface language provides separation of clients and tool providers. Their autonomy will allow information consumers and providers to make progress independently, mirroring the past decades of SQL use.
Motivation
Basic database systems are being extended to encompass wider access and analysis capabilities. Today rapid progress is being made in information fusion from heterogeneous resources such as databases, text, and semi-structured information bases [WiederholdG:97]. Results of this research are being transferred to practical settings. The objective of many database technology extensions is to provide more capabilities for decision-making. However, the decision maker also has to plan and schedule actions beyond the current point-in-time. Databases make past and nearly current data available, but tools that predict future states are required for projecting the outcome at some future time of the decisions that can be made today. [StonebrakerK:82] proposed extensions that allow hypothetical relations to be defined within the schema. The data represented in such relations is to be computed using rules and other stored data, and could include projected values [StonebrakerK:82]. Such computational features are now included in several database systems, and are expected to be touted soon as part of Microsoft's SQLserver. For substantial predictions and alternative futures it seems better to rely on exiting and well-developed simulation tools. The predictive requirements for decision-making have been rarely addressed in terms of integration and fusion [Orsborn:94].
The tools that are available for projecting future states include spreadsheets with formulas predicting expected results, planning models, business-specific simulations, and continuous simulations, as used for weather forecasting. They all require computations to produce results, sometimes they may precompute values and store them for later retrieval. We will refer to all of them as simulations. Actual future states to be computed will be affected by two types of factors: 1. actions initiated by the decision maker, and 2. failures to execute actions correctly, events due to nature, and actions of others. Simulations have input parameters that allow setting of such expectations. Some of these parameters are best set by the decision maker, and others by experts. For instance, in a business setting, a product manager may set the amount of a product investment, but experts will contribute, say, the size of the market base, expected interest-rates, failure probabilities based on historical records, and the like. A simulation will provide for any investment made a given time, the likely sales, profits, and associated risks.
Database technology is not very visible in this domain. In simple cases the expected future state is projected from a back-of-the envelope estimate, counting on individual experience. Dealing with the increasing complexity of the modern world and the widening range of alternatives demands computational assistance. The most common tool being used for planning and documenting predictions is the spreadsheet. In situations where the amount of data is modest and relatively static, files associated with spreadsheets have entirely supplanted the use of database technology, and extensions to allow sharing of such files are being developed [FullerMP:93]. Business-specific simulation tools allow convenient entry of alternative decisions and might store intermediate results information into their own file structures. Analyzing the stored alternatives helps in selecting the best course-of-action [LindenG:92]. Since for the future multiple values are obtained, time-oriented database extensions, supporting a past history [Snodgrass:95], have not been adequate. To be effectively used, predicted values must be labeled with the parameter settings and systems assumptions that led to them. A weak point in predictive systems that store simulation results is that the volume of possible alternatives is huge, and any stored information becomes very rapidly invalid, as time and events pass on. We find hence in practice much more ad-hoc use of simulations. The effect is that simulations are not integrated into more comprehensive information systems, and data is often transferred (in and out) by cut-and-paste technology. The problem has been recognized in military planning; quoting from [McCall:96]: The two `Capabilities Requiring Military Investment in Information Technology' are:
`1. Highly robust real-time software modules for data fusion and integration;
`2. Integration of simulation software into military information systems.’
The database paradigm, providing clients with anywhere, anytime access to valid information, defined in a schema, supported by a substantial infrastructure, should also be attractive for data about the future. Our SimQL research has investigated such an approach and developed a language tool suitable for integration with database technology.
Infrastructure:
In order to bring prediction into the database paradigm we can exploit a wealth of available information technologies, reaching beyond the database community. We have made great strides in accessing information about past events, stored in databases, object-bases, and the World-Wide Web. Access to information about current events is also improving dramatically, with real-time news feeds and on-line cash registers. To serve projections we must expand the temporal range into the future, deal with multiple alternative projections, and manage the uncertainty of such projections.
Databases
The importance of rapid, ad hoc, access to data for planning is understood by database specialists, but should not be limited to historic data from databases. This audience understands database capabilities well, so will not belabor them. The invention of the schema [McGee:59] and of formal query languages [Codd:72] that depend on the schema has transformed application-specific file programming into an independent services industry. Eventually, multiple, remote databases could be queried [Litwin:83]. Modern versions of SQL provide now also remote access [DateD:93]. Extensions to SQL to manage historical data are becoming well accepted [Snodgrass:95]. Data warehouses that integrate data into historic views are becoming broadly available [Widom:95].
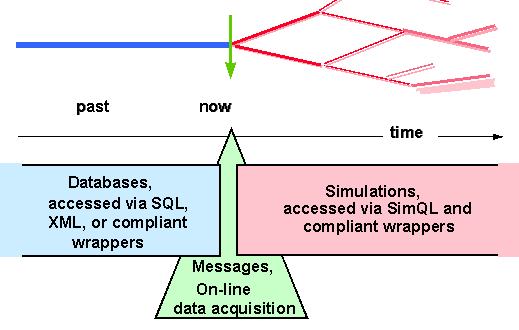
Figure 1: The Place of Simulation Access in Information Systems
Planning systems
Planners must consider alternate futures, so that an information model that supports planning must handle a tree of data beyond
now, as shown in Figure 1. Branches of the plan have associated uncertainties. Planning systems developed in Artificial Intelligence do deal with alternatives and uncertainties [TateDL:98]. They model processes otherwise only performed in a planner's mind. That is, the planner sketches reasonable scenarios, mentally developing alternate courses-of-action, focusing on those that had been worked out in earlier situations. Such mental models are the basis for most decisions, and only fail when the factors are complex, or the planning horizon is long. Human short-term memory can only manage about 7 factors at a time [Miller:56]. That matches the number of reasonable choices in a chess game, so that a game as chess can be played about as well by a trained chess master as by a dumb computer with a lot a memory. But chess is simpler than most of the real world. To help the client, tools for managing uncertainty, pruning the space of alternatives, presentation of viable choices, and their comparison become essential.Planning systems provide for computing the uncertainty forward in time, as the tree of alternatives widens. If values (i.e., income, profit, position, benefits, inventory) at the end-points are known, planning systems can perform the backwards calculations to obtain the current-net-value for decisions to be made now, or at intermediate points in the future [Tate96]. Unfortunately, they tend to be data poor. Instead of matching conditions with actual information, they tend to depend on equations, derived from mining past data to compute the projections. Since most planning systems store all their information internally, they also tend to be static. Recent events, and the progress of time, are not directly incorporated.
Simulations
Decision-making in planning depends on knowing past, present, and likely future situations. Justifiable projections require entering current data, and computing results using well-defined models. We find such models in existing simulations. Replacing manual planning with simulations has the benefits that it becomes easy to dynamically re-execute the planning process when situations change. Events, expected at planning time, may change in relevance. Uncertainties reduce as time passes. Keeping information models for planning up-to-date is hence much work, and is unlikely to happen without tools that enable easy access to simulation results within dynamic decision-support systems. Integration of simulation results into effective client systems distinguishes our work from the objective of building grander simulations, which motivates the simulation community.
To assess the future thoroughly we must access and execute simulations dynamically. Spreadsheets use simple formulas. It is up the spreadsheet designer to identify columns or rows as being results representing future states. Simulations typically deal with time explicitly. They employ a wide variety of technologies, including continuous equational models and discrete, time-step models. Many simulations are available from remote sites [FishwickH:98]. Simulation access by more general information systems should handle local, remote, and distributed simulation services. Distributed simulations can also communicate with each other [MillerT:95]. These interact using highly interactive protocols (HLA) [IEEE:98], but their results are not now accessible to general information systems [Singhal:96]. If the simulation is a federated distributed simulation, as envisaged by the HLA protocol, then one federation member may supply the data to the decision-making support system, by first aggregating data from detailed events to the level that is appropriate for initiating planning interactions.
Uncertainty
Extrapolating from a past into the future creates uncertainty. Uncertainty is an essential aspect of planning, and has been studied in a variety of abstract settings [BhatnagarK:86]
, and this research direction is ongoing. . The Artificial Intelligence (AI) community has a long history of computing with a variety of uncertainty measures and some researchers have found commonalties in approaches that make integration feasible [KanalL:86]. It will be important to bring this research into practical, information-based planning systems.Pruning
Alternate future scenarios represent not only choices that can be made by the client, but also events outside of the decision-makers control, as responses by others or acts-of-nature. When the projections become detailed and planning horizons extend far, the space of alternatives becomes immense. At each ply the alternatives multiply, and pruning or coalescing of branches becomes crucial. As time passes, opportunities for choosing alternatives disappear, so that the future tree is continuously chopped off at the root as the now marker marches forward [CliffordEa:97].
Today, the initial pruning is mainly done intuitively or interactively, with participants sharing whiteboards. Available tools are video-conferences and communicating smartboards, sometimes augmented by pasting results that participants extract from isolated analysis programs. For instance, a participant may execute a simulation to see how a proposal would impact people and supply resources. Financial planners will use spreadsheets to work out alternate budgets, and show a subset of the parameters to others. Automated pruning may be based on low probabilities, or on low potential loss or gain. Coalescing of low-valued branches can simplify computation, and allow expansion when conditions change. Automation of these techniques will be a challenge.
The SimQL Approach
The concept of our simulation access language, SimQL, mirrors that of SQL for databases. Instead of requesting stored information SimQL initiates interactions with a computational module. These modules are assumed to be external and substantial, so that the overhead of accessing them is worthwhile. The modules, or rather their wrappers, accept input parameters, including the desired future time, and return corresponding result values. Typical inputs parameters implicitly specify actions, say making a certain investment, or choosing an available alternative. For example, a client may specify a decision to use air freight rather than road transport. The computations may generate further alternatives, say, the possibility or not of a snowstorm causing delays in Chicago.
To make the results obtained from a simulation clear and useful for the decision maker the interface must use a simple model. Computer screens today focus on providing a desktop image, with cut and paste capability, while relational databases use tables to present their contents, and spreadsheets use a matrix with hidden formulas. To be effectively used simulations should also present a coherent interface model. In terms of system structure, we follow the accepted SQL approach. Note that SQL is not a language in which database management systems are written; those may be written in C, Ada, etc.. Rather, SQL is a language to describe, select, and fetch results for further use in information systems. The databases themselves are owned and maintained by others, as domain specialists and database administrators. Similarly, use of SimQL enables access to the growing portfolio of simulation technology and predictive services maintained by experts in the simulation community. Having a language interface will overcome the discontinuity now experienced when predictions are to be integrated with larger planning systems.
The research carried out under the proof-of-concept support include three phases:
Language Concepts
There are two aspects to the SQL language, mimicked by SimQL:
Using similar interface concepts simplifies the understanding of clients and also encourages seamless interoperation of SimQL with database tools in supporting advanced information systems. There are differences, of course, in accessing past data and computing information about the future:
Since we expect to often have to integrate past information form databases with simulation results we start with the relational model and SQL. However the objects to be described have a time dimension and an uncertainty associated with them. We hence used a simple object extension as the data representation for SimQL.
Resource access
We focused on accessing pre-existing predictive tools. Wrappers are used to provide compatible, robust, and `machine-friendly' access to their model parameters and execution results [HammerEa:97]. Our wrappers also convert the uncertainty associated with simulation results (say, 50% probability of rain) to a standard range (0.5 out of 1.0 -- 0.0). If the simulation itself does not provide a value that can be used, or converted, for its uncertainty the wrapper may estimate a value based on experience of its author or the wrapping expert. The obtained or estimated uncertainty value is attached to all results obtained in a single query.
This paper focuses on the language and interface aspects, but we will first briefly list the simulations that were wrapped in our experiments to provide information to the SimQL interface. The range illustrates that SimQL is not a point solution.
Just as a client application can invoke multiple databases, a application can also employ multiple SimQL simulations. Our experiments only combined simulations b. and c., selecting the forecast based on the lowest uncertainty at a selected day in the future. Still, these experiments demonstrated the applicability of SimQL to a range of settings and provides a foundation for further development of SimQL.
Language design
By borrowing from SQL and the database programming paradigm we can make the SimQL schema language and the query language easy to grasp. Also, given that this was intended as a proof-of-concept effort, we preserved the syntax and most of the semantics of the SQL language and its interfaces by providing only minimal functionalities and data types needed. It is important to note that SimQL, just like SQL, has a schema component as well as a query component. A schema describes the capabilities, the data that can be obtained and the parameters that queries can use. For SimQL the schema identifies which simulation variables are subject to being reported, and which simulation variables are available for parameter setting by queries. In a business simulation sales and profits will be queryable, while investment would be a parameter that can be set. Interest rates may not be settable in the schema, but managed by the simulation owner. Such a constrained access to simulation internals assure that all business proposals in some system context use identical interest-rate assumptions.
The SimQL language is indeed nearly identical to SQL, and was implemented using an existing SQL parser
. We replaced the SELECT term with ESTIMATE, and replaced CREATE DATABASE with CREATE MODEL. We added to the schema CREATE statements the attributes IN, OUT, and INOUT. We removed the UPDATE statement. In the code generators we replaced the functions that access stored data with functions that deliver the query parameters to various simulations, collected and returned the results.A simple illustration of the similarity of SQL and SimQL can be gleaned from showing two queries, the first one addressed to a database and the second one to a simulation:
1. SELECT Temperature, Cloudcover, Windspeed, Winddirection FROM
WeatherDB WHERE Date = `yesterday' AND Location = `ORD'.
2. ESTIMATE Temperature, Cloudcover, Windspeed, Winddirection FROM
WeatherSimulation WHERE Date = `tomorrow' AND Location = `ORD'.
For this particular
ESTIMATE statement the SimQL software, as directed by the schema, initiates access to a wrapped weather simulation, likely one available on the web. The specifics of the language as implemented can be found on our webpages, at http://www-db.stanford.edu/LIC/SimQL.html and …/SimQLspec.html, but will show no surprises to anyone knowing SQL. The innovation of SimQL is not in the language, but in the information it accesses.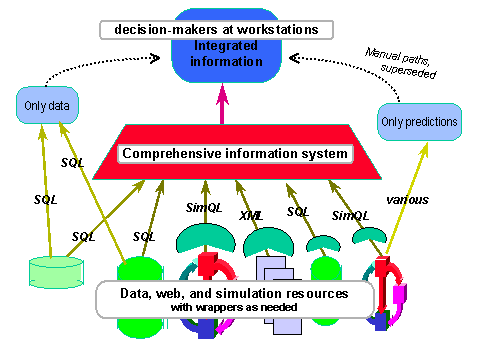
Figure 2: SimQL usage in an integrated, comprehensive information systems
Interfaces
While designing the underlying system and its interfaces, it is important to draw distinctions between the decision-making clients, builders of planning systems, wrapper developers, simulation developers, and finally the SimQL system developers. We envisage overall a mediated architecture, accessing databases as well as simulations, as sketched in Figure 2.
The clients need only the results, and tend to be removed from direct use of SimQL and SQL. We expect that there will be an information system, providing integration and mediation among heterogeneous components. such a system often uses HTML interfaces to day, although for recurring business uses XML is preferable. Our demonstration provided only a minimal information system and HTML-compliant client access.
System builders will access simulations through SimQL and databases through SQL. If access to the web is required XML or HTML interfaces might be used. For comparison, merging of information, and planning-specific computations they are likely to use languages as C and C++.
Wrapper developers must write SimQL-compliant interface code for access by the information systems. Each of the legacy simulation types we have used required different technology. Spreadsheets were accessed through MS COM interfaces, while simulations on the web required HTML scripts. Our programs that assembled the wrappers were written in C++. System developers will also develop tools to aid in the creation of wrappers, as now done for non-conforming data resources [AshishK:97]. In an eventual practical setting wrapper generation may be allied with simulation providers who want broader audiences or with system builders who need simulation resources.
People who write and maintain the actual simulations often use specialized languages. Some important work was done in
SIMULA. Planning systems have often used LISP or its dialects. Many large simulations are still written in FORTRAN, making their wrapping a challenge. If such a simulation has been made available for external use, via an API or the web, the wrapper developer may actually be quite innocent of the actual language used for the simulation.The SimQL language system again shows many parallels to a database management system. It includes a catalog of simulation resources and a schema repository for them; those are direct analogs to SQL catalogs and schemas. The contents of the catalog differs however, because the description of a simulation requires different attributes. We also assume that the simulation resources are always distributed, so that there are no default local access paths.
Schema and wrapper services
The task of a wrapper developer is to make a simulation schema available to builders of planning systems. After writing a SimQL wrapper for a simulation, the developer must inform the SimQL environment that such a wrapper exists. A
REGISTER statement enables a wrapper developer to enter information about the wrapper, and hence implicitly about the wrapped simulation as metadata kept in the SimQL system. Because wrappers can comes in various forms, we borrowed some object-oriented concepts to make the REGISTER statement flexible and scalable enough to handle complex wrappers. A wrapped simulation can be viewed as having a number of attributes and simulation methods. In a REGISTER statement, a wrapper developer can specify different ATTRIBUTEs of a simulator such as its performance and its accuracy in the past, and the METHODs available to the clients for invoking the simulation.Once a wrapper is registered in the SimQL metadata repository, the wrapper developer needs to create a simulation method reference for each intended type of client based on the registered wrapper. This is because
The
CREATE MODEL statement enables the wrapper developers to do define a variety of methods for each wrapper, mimicking the VIEW capabilities in SQL. A wrapper developer can specify a simulation model for each client based on the registered wrapper along with its input/output variables (specified by IN, OUT, or INOUT) and its associated method (specified in the AS clause). The CREATE MODEL statement constructs the core of the SimQL schema. Other metadata management language statements include DROP MODEL, HELP, etc.The client application uses the
FROM clause in the ESTIMATE statement to select the method to be invoked. For instance, the model created for the business model represented in the spreadsheet only exposed the investment amounts, and the year or which the result was desired as IN variables, and the value of the investment, paired with its probability as the OUT variable. Interest rates, taxes, and business growth assumptions and their computations remained hidden from the client, being under control of the author of the spreadsheet. Another scenario could have given the client also a choice of investment policies.All these SimQL schema language elements are very similar to the SQL views (i.e.,
CREATE MODEL is analogous to CREATE VIEW, etc.), both in syntax and concept. These similarities make the language easy to understand and expand for someone trained in database technology.Query facilities
The initial SimQL query language was built around the
ESTIMATE statement. Just as SELECT in SQL is used to query data in a table or a view, ESTIMATE in SimQL is used to invoke a simulation and obtain the results from a created simulation model. Simulation clients specify the target simulation models via the FROM clause, the input variables via the WHERE clause, and the parameters driving the simulation via the HAVING clause.Despite all the similarities, SimQL is different from SQL in many ways, among which the following are the most prominent.
The capability to have multiple methods can also enable a client service which allows deeper inspection of a simulation, when the client needs explanations pertaining to a computed result. It is up to the wrapper developer and the simulation provider how many parameters can be labeled as
OUT types in some METHOD.Implementation
The SimQL implementation consists of a SimQL server, several SimQL clients, a interface to wrappers, several wrappers for simulations, and several actual simulation, as sketched in Figure 3. The four programs wrtiien to implement SimQL are depicted by ovals. Figure 3 combines the information flows during creation by the developer, subsequent querying by the client, as well as flows of the actual predictive results (bold) and possible error feedbacks (dashed).
The proof-of-concept implementation was achieved by modifying an existing public SQL implementation (RedBase). This approach allowed rapid implementation, although the result is not as tight as a specific implementation would have been. The benefit was to gain rapid experience with compiling SimQL. The functions implemented were
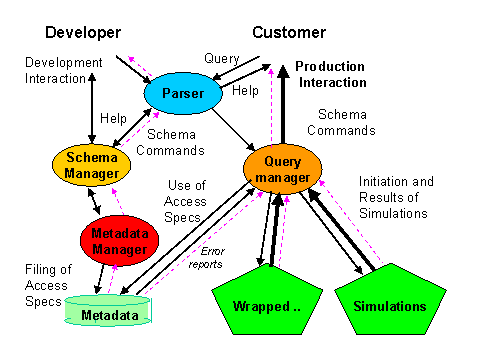
Figure 3: The SimQL prototype implementation
Written in Lex and Yacc, the SimQL parser takes SimQL statements from the clients and interprets them. After simple syntactical checking, the parser parses each statement to generate a parse tree and interprets the statement by resolving all the nodes on the tree. During the interpretation, more complex syntactical checking is performed. Depending on the type of the SimQL statement (schema vs. query), the parser packages the parsed statement accordingly and sends it to the SimQL Schema Manager or the SimQL Query Manager. A lower-level SimQL Metadata Manager was implemented to handle the file operations required by the Schema Manager and the Query Manager. The metadata files on disk store permanent information about registered wrappers and their corresponding attributes and methods, defined simulation models and their input/output variables as well as their corresponding wrappers. These metadata files are read-only to the SimQL Query Manager, which does schema lookup before accessing a required simulation.
The data structures used in all four components of the SimQL implementation originated from the SQL implementation and were adapted for simplicity. The whole implementation has about 6,000 lines of C and C++ code and is partitioned into those four modules. The SimQL Schema Manager, the SimQL Query Manager, and the SimQL Metadata Manager are written in C++, with each manager represented by a super C++ class and each SimQL statement having a method in a class. The use of object-oriented programming here has made those managers very scalable and expandable. Each of the managers can be independently compiled for testing purposes.
Results
The SimQL implementation realized the following SimQL elements/features.
The system was tested on the wrapped weather-forecasting model in a local setting and performed as planned. To test wrapper reusability we ported the wrapper code to a second spreadsheet and determined that the adaptation to new input-output parameters was straightforward.
Assessing the current state of the world
We have focused on using simulation to assess the future. There is however an important task for SimQL in assessing the current state. Databases can never be completely current. Some may be a few minutes behind, others may be several days behind in reporting the state of resources and events. Information about external markets and competitors often lags even further behind, although it is a crucial element in decision-making.
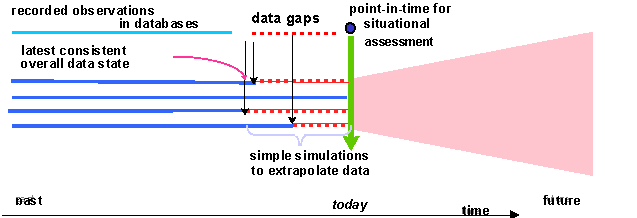
Figure 4: Even the present needs SimQL
The consistency preserving approach in database technology is to present all data at the same point in time, which reduces all information to the most distant point-in-time of all valid sources, i.e., with the worst lag. The client of multiple databases has to make a choice between using the latest consistent data, which may be several days out-of-date, or use an inconsistent mix of all data as available today. For planning it is better to use the actual latest data from each source, and then project the information to the current point-in-time. We believe that a decision-maker, when faced with this choice, will use the most current data and informally extrapolates all information to today.
Supporting such extrapolations with a convenient tool, that fits into the same database paradigm, has obvious utility. Computer generated extrapolations from the latest known database states to the current point-in-time can provide a consistent, even if still somewhat uncertain picture of, say, where supplies needed for manufacturing are now, where transportation or warehouse resources are stressed, and what the state is of assemblies that need the supplies.
SimQL can support this requirement easily since it provides an interface that is consistent over both databases (assumed to have data with certainty 1.0) and simulations, as shown in Figure 4. The combined known and extrapolated results will be more useful than a perfect, auditable picture of the situation 2 days ago. Using SimQL-initiated simulations in the gaps improve quality and consistency of the current information, and can also report the remaining uncertainty. Such simulations will typically be simple, and in most cases no tree of alternatives needs to be supported.
Future work
We have not yet transitioned SimQL to any real simulation clients and thus we do not know how receptive they will be towards the language. We need feedback to validate the language, but even more on the information systems setting..
Our prototype SimQL only delivers that data to a browser, an application, or an information systems. For the information systems we foresee we will have to place the results into a temporal tree that is rooted in
today. When time moves on, the root moves forward as well and past ESTIMATEs now become data, to be replaced as true SQL information becomes available. At that time it may also be wise to recompute all ESTIMATEd values, by re-invoking the simulations. In general, successive answers from a simulation will always differ if the time origin has changed.Our work in SimQL provides the interfaces for planning tools, but did not extend to implementations of the information systems with alternative branches that motivated our research.
All vertices of the tree must be labeled with the parameters used in any simulation. Functions to allow planning computations to process the result values in the tree have to be provided. Such computations split, combine, and normalize certainty factors. They can reduce benefits and costs to net-current-values at any intermediate point-in-time. Client interfaces should also report cross-sections, namely the values at all branches of the tree for a given point-in-time.Interfaces languages such as SimQL should also be able to exploit emerging conventions for information systems. For instance, they might use XML as an object representation, a CORBA communication framework, and `Java' for client-based services.
We plan to seek further support for the development of SimQL concepts in a setting where a realistic evaluation by potential clients can take place. We also encourage others to explore this or similar directions, because the broadening from databases that look at history to information systems that include the future is more than any single effort can achieve.
Conclusion
We have investigated the feasibility of SimQL and gained experience for a more realistic SimQL project. We have some early results, indicating that highly diverse predictive tools may be accessed with a consistent interface language as SimQL. We also expect feedback to occur to the traditional database domain; for instance, uncertainty may also be associated with past data, but not now treated within the database paradigm.
Despite the limitations of our initial prototype, we believe that high-level simulation access has the potential of a major broadening of future information systems. This early report of our experience seems warranted, since the potential for this broadening of the database approach has much potential. An increasing number of simulations are available on the Web, but they are all difficult to integrate into information systems without an access language. Because of the importance of simulations to decision-making, we expect that concepts as demonstrated in SimQL will in time enter large-scale information systems and become a foundation that will make a crucial difference in the way that simulations will be accessed and managed. In turn, convenient access to simulations opens up new opportunities and research avenues for information systems that support decision-making.
Acknowledgments
This research was supported by DARPA DSO, Pradeep Khosla was the Program Manager; and awarded through NIST, Award 60NANB6D0038, managed by Ram Sriram. The original SQL compiler, MiniRel, was written by Mark McAuliffe, of the University of Wisconsin – Madison; and modified at Stanford by Jan Jannink and Dallan Quass under the direction of Jennifer Widom (RedBase). James Chiu, a Stanford CSD Master’s student, provided and wrapped the gas station simulation. Experience in accessing the results of large, distributed simulations was gained in a related project [MalufWLP:97]. Julia Loughran of ThoughtLink provided useful comments to a presentation of portions of this work to our military sponsors [WiederholdJG:98]. We also thank unknown reviewers of earlier version of this paper for valuable feedback
References
[AshishK:97] Naveen Ashish and Craig A. Knoblock: "Semi-automatic Wrapper Generation for Internet Information Sources"; Second IFCIS Conference on Cooperative Information Systems (CoopIS), Charleston, South Carolina, 1997.
[BeringerTJW:98] Dorothes Beringer, Catherine Tornabene, Pankaj Jain, and Gio Wiederhold: "A Language and System for Composing Autonomous, Heterogeneous and Distributed Megamodules"; DEXA International Workshop on Large-Scale Software Composition, IEEE, August 1998.
[BhatnagarK:86] Bhatnagar and L.N. Kanal: "Handling Uncertain Information: A Review of Numeric and Non-numeric Methods"; in Kanal and Lemmer(eds.): Uncertainty in AI, North-Holland publishers, 1986.
[CliffordEa:97] James Clifford, Curtis E. Dyreson, Tomás Isakowitz, Christian S. Jensen and Richard T. Snodgrass: "On the Semantics of `Now' in Databases"; ACM Transactions on Database Systems, Vol. 22 No. 2, June 1997, pp. 171-214.
[Codd:72] E.F. Codd: "Relational Completeness of Data Base Sub-Languages"; in Rustin (ed): Data Base Systems, Prentice-Hall, 1972, pp.65-98.
[DateD:93] Chris J. Date and Hugh Darwen: A Guide to the SQL Standard, 3rd ed.; Addison Wesley, June 1993.
[FishwickH:98] Paul Fishwick and David Hill (eds.): 1998 International Conference on Web-Based Modeling & Simulation; Society for Computer Simulation, Jan 1998,
http://www.cis.ufl.edu/~fishwick/webconf.html.[FullerMP:93] David A. Fuller, Sergio T. Mujica, José A. Pino: "The Design of an Object-Oriented Collaborative Spreadsheet with Version Control and History Management"; SAC’93, Proceedings of the 1993 ACM/SIGAPP symposium on Applied computing: States of the art and practice, pp. 416-423.
[GarciaMolinaBP:92] Hector GarciaMolina, D. Barbara, and D. Porter: "The Management of Probabilistic Data"; IEEE Transactions on Knowledge and Data Engineering, Vol.4, No. 5, October 1992, pp. 487-502.
[Gruber:93] Thomas R.Gruber: ``A Translation Approach to Portable Ontology Specifications''; Knowledge Acquisition, Vol.5 No. 2, pp.199--220, 1993
[HammerEa:97] J. Hammer, M. Breunig, H. Garcia-Molina, S. Nestorov, V. Vassalos, R. Yerneni: "Template-Based Wrappers in the TSIMMIS System"; ACM Sigmod 26, May 1997.
[IEEE:98] P1561, Draft IEEE Standard for Modeling and Simulation (M&S) High Level Architecture (HLA); IEEE, 1998.
[INEL:93] Idaho National Engineering Laboratory: "Ada Electronic Combat Modeling"; OOPSLA'93 Proceedings, ACM 1993.
[Jiang:96] Rushan Jiang: Report on the SimQL project; submitted to Prof. Wiederhold, CSD Stanford, August
[KanalL:86] L.N. Kanal and G.F. Lemmer: Uncertainty in Artificial Intelligence ; North-Holland pubs., 1986.
[LindenG:92] Ted Linden and D. Gaw 1992: "JIGSAW: Preference-directed, Co-operative Scheduling," AAAI Spring Symposium: Practical Approaches to Scheduling and Planning, AAAI, March 1992.
[Litwin:83] Witold Litwin: "MALPHA: A Multidatabase Manipulation Language"; European Teleinformatics Conf., Varese Italy, North-Holland, Oct.1983.
[McGee:59] W.C. McGee: "Generalization --- Key to Successful Electronic Data Processing"; J. ACM, Vol.6 No.1, Jan.1959, pp.1--23.
[Kohavi:96] Ron Kohavi: Wrappers for Performance Enhancement and Oblivious Decision Graphs; PhD thesis, Stanford University CSD, 1996.
[MalufWLP:97] David A. Maluf, Gio Wiederhold, Ted Linden, and Priya Panchapagesan: "Mediation to Implement Feedback in Training"; CrossTalk: Journal of Defense Software Engineering, Software Technology Support Center, Department of Defense, August 1997.
[McCall:96] Gene McCall (editor): New World Vistas, Air and Space Power for the 21st Century; Air Force Scientific Advisory Board, April 1996, Information Technology volume, pp. 9.
[Miller:56] George Miller: "The Magical Number Seven Two"; Psych.Review, Vol.68, 1956, pp.81-97.
[MillerT:95] Duncan C. Miller and Jack A. Thorpe: "SIMNET: The Advent of Computer Networking"; Proceedings of the IEEE, August 1995, Vol.83 No.8, pages 1116-1123.
[Orsborn:94] Kjell Orsborn: "Applying Next Generation Object-Oriented DBMS for Finite Element Analysis"; ADB conference, Vadstena, Sweden, in Litwin, Risch: Applications of Database', Lecture Notes In Computer Science vol. 819, Springer, 1994.
[Singhal:96] Sandeep Singhal: Effective Remote Modeling in Large-Scale Distributed Interactive Simulation Environments; PhD Thesis, Stanford CSD, 1996.
[Snodgrass:95] Richard T. Snodgrass (editor): The TSQL2 Temporal Query Language; Kluwer Academic Publishers, 1995,
[StonebrakerEa:82] Michael Stonebraker et al.: "A Rules System for a Relational Data Base System"; Intl.Conf.on Data and Knowledge Bases; Jerusalem, Israel, Jun. 1982.
[Tate:96] Austin Tate: Advanced Planning Technology; AAAI Press, 1996.
[TateDL:98] Austin Tate, Jeff Dalton and John Levine: "Generation of Multiple Qualitatively Different Plan Options"; Proceedings of AIPS-98, Pittsburgh, June 1998;
[Wiederhold:93] Gio Wiederhold: "Intelligent Integration in Simulation"; MORS Mini-symposium, Fairfax VA, Military Operations Research Society, Alexandria VA, November 1993.
[WiederholdG:97] Gio Wiederhold and Michael Genesereth: "The Conceptual Basis for Mediation Services"; IEEE Expert, Intelligent Systems and their Applications, Vol.12 No.5, Sep-Oct.1997.
[WiederholdJG:98] Gio Wiederhold, Rushan Jiang, and Hector Garcia-Molina: "An Interface for Projecting CoAs in Support of C2; Proc.1998 Command & Control Research & Technology Symposium, Naval Postgraduate School, Monterey CA, June 1998, pp.549-558.
[Widom:95] Jennifer Widom: "Research Problems in Data Warehousing"; Proceedings of the 4th Int'l Conference on Information and Knowledge Management (CIKM), November 1995.