WAC Workshop at Stanford
In June 2012 we held an archiving workshop at Stanford University.
A number of students and faculty attended from Old Dominion and Harding
Universities. Frank McCown of Harding organized the event.
Special about this workshop was that it brought together different disciplines,
like library science, law, and computer science.
See slides from the presentations by
Eric Hetzner and
Aaron Binns.
We heard about archiving efforts in a number of institutions, both
within and outside of the Web Archive Cooperative. For many of the
students this workshop was their first visit to Stanford, and their
first exposure to events of this type.
Quotes from participants:
"This was so exciting!"
"This was a semester's worth of material in one day."
"I got so many new ideas today."
"It was great to observe how the senior scientists questioned each other to learn."
In addition to energizing and inspiring all participants, the workshop
was an opportunity for the project principals to coordinate. We consequently
decided to develop conversion technology from the 280TB Stanford
WebBase holdings to the Web Archiving (WARC) format. This format is
used at the Internet Archive, as well as the Library of Congress and
the California Digital Library. The Old Dominion Memento project builds
on the standard, as do a number of tools, like the Wayback Machine. We
therefore expect that this development effort will serve to unify
some significant holdings.
Post Workshop Technical Activities
Our WAC workshop in June 2012 kicked off a number of technical efforts.
Our decision to unify our formatting in support of the WARC standard was
realized.
WebBase
crawls may now be requested via a Web interface in
either their original formats, or as WARC formatted packages.
WAC investigator Michael Nelson's presentation at the workshop stressed
the importance of projects that make Web archives useful
today,
as opposed to merely promising payback years from now. Such products,
the arguments goes, will ensure enduring interest in archiving activities.
In pursuit of this goal our Stanford WAC contingent embarked on an unusual
employment of archives:
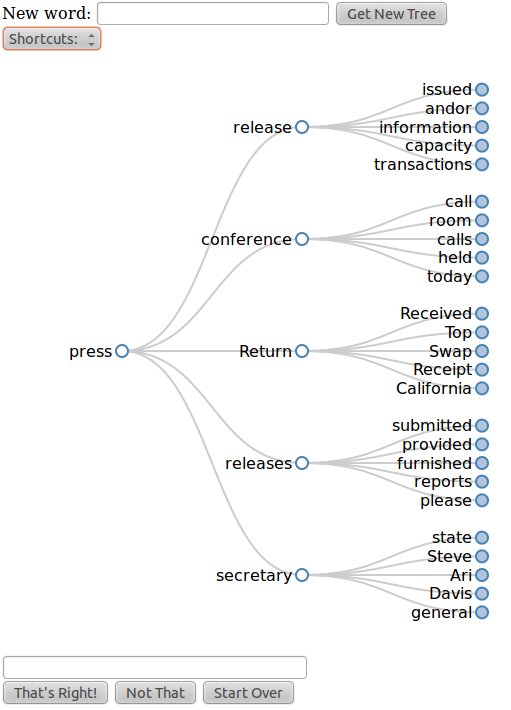
EchoTrees. This small, ongoing, exploration
attempts to employ archives to support communications of a mute quadriplegic
collaborator with conversation partners. This collaborator,
Henry Evans, types communications on his laptop using a head
tracker. For his conversation partners, the wait for answers during
Henry's conversation turns is passivating and discouraging. Our experimental
solution is to use varying Web and other collections to predict
multiple phrase outcomes from any word that Henry types. These outcomes
are visualized in a word tree, as exemplified in the following figure from
our technical report
EchoTree: Engaged Conversation when Capabilities are Limited:
Collocated or remote conversation partners can see these visualizations
on their Web browsers. They can manipulate the trees, and discuss possibilities
with each other. Most importantly, conversation partners propose to Henry some
phrase outcome he might have in mind, saving him typing time. We are in
the process of evaluating various aspects of this design.
Panel Discussion at Infolab Workshop
In April, 2013 during our
biennial
Infolab-wide
workshop the WAC project organized a panel
Data in the Cloud: For What and For Whom?
The workshop was organized this time as a collaboration of universities at Stanford, UC Berkeley, UC Santa Cruz,
UC Merced, Cal Poly, and Davis.
The workshop was attended by some 200 visitors from those universities, as well as
surrounding Silicon Valley industry. The panel stimulated a discussion on implications
of moving large segments of personal information into the cloud, which is generally
owned by private interests. We heard from panelist
Brewster Kahle
about the Internet
Archive having been served one of the controversial "National Security Letters."
Jennifer
Granick of the Stanford Center for Internet and Society summarized
for the audience legislative developments around information privacy
and digital rights
management.
Shaukat
Shamim of Dezine provided examples for creative outcomes made
possible by contributions of information to the 'commons.'
On the sidelines of this event it was decided to donate a snapshot of Stanford's
WebBase to the Internet Archive. This effort will involve conversion of the
280TB (uncompressed) collection into the WARC format, as well as transfer and integration
into the Internet Archive collection. We will use our 60 node compute cluster to
accomplish this task.
Static Project Information
Challenges
Challenge: Describing Resources
Each federation member has a
set of ``resources'', e.g., web crawls, query logs, crawling software,
etc. To be usable, each resource needs to be described in a way that
can be understood for other federation members. How was the resource
obtained? On what dates? What does it contain? Who can access the
resource? Who do we ``compare'' archives and their holdings? While
standards are emerging, their resource descriptions are not yet
detailed enough to allow integration with other resources. The
challenge is to identify descriptions that truly facilitate
experimentation and integration, and at the same time are reasonable
for the resource owner to generate.
-
Thrust 1 (Resource Description): Create a comprehensive ``taxonomy'' of descriptive
features and access mechanisms (APIs) for a wide range of resource types.
Develop a cost/benefit ratio for each feature/mechanism that
describes how difficult it is to obtain/implement the feature/mechanism, and how useful it is
to support experimentation and research.
Identify, promote and develop metrics for quantifying and comparing
archives.
Study how to include new features/mechanisms in existing or new standards.
Build a reference implementation for an archive
that supports advanced resource description/access
for a variety of resources.
Challenge: Resource Discovery and Characterization.
A WAC needs a discovery service that lets researchers find resources of interest.
Resource owners can manually register resources
at the discovery service, or the service can automatically
harvest information about emerging resources
(e.g., by monitoring crawler traffic at Web sites).
If a resource is not fully described, the discovery service
may be able to analyze the resource and extract
its characteristics (e.g., site depth of a crawl, coverage,
diameter).
-
Thrust 2 (Discovery)
Study and evaluate options for a resource discovery service.
We will explore three goals for such a service:
(1) the manual or automated discovery of entire existing Web related
archives; (2) the selection
among known archives of the ones that
support a specific research question; and (3)
the identification of individual resources from within the
selected archives.
We will also develop tools for characterizing discovered archives,
especially for the case where the archive does not provide rich
descriptive metadata.
Characterization of an archive includes elements such as an estimate
of the archive's coverage, particulars of the crawling parameters,
like dates/frequencies, crawl duration, depth, per-site ceiling on the
number of collected pages, content statistics, and link structure.
Using open-source software as much as possible,
we will build, operate, and evaluate a discovery service for our WAC.
Finally, we will also support what we call forward discovery,
i.e., the identification of candidates for future archiving.
For WAC forward discovery we will provide a clearinghouse
where the community can express recommendations.
Such a clearinghouse is needed, because
recommending parties do not often themselves possess archiving
capacity. On the other hand, the community at large is an
indispensable resource for identifying niches of interest on the Web
that might be of importance in the future.
Challenge: Linking and Combining Resources.
The WAC provides integrated access to independent resources. This
integration requires sophisticated resource and metadata translation
mechanisms. For instance, URLs in one archive need to be mapped to
ones in another; annotation tags in one resource need to be translated
to their synonyms in another. Redundant (or approximately redundant)
objects need to be identified, merged and possibly exploited (e.g., if
an archived URI is damaged, are there redundant or similar URIs that
can be substituted?). Inconsistencies in the way
resources were gathered need to be resolved, or at least described.
For example, how do we unify two Web page crawls, one that visited
sites every 3 days and another that visited sites every 5 days?
-
Thrust 3 (Archive Linking)
We will develop mechnisms for integrating diverse archives,
and will apply the mechnisms to site reconstruction
(from various archives) and archive views (a logical fusion
of resources from multiple sources).
Since integration issues are so challenging, we will
set up an experimental testbed with small but diverse resources.
The testbed will contain several crawls of the same target sites,
each obtained with different crawlers and using different parameters.
The testbed will also contain related resources, e.g., the tags
at Delicious for the same set of sites.
The testbed will let us study and quantify differences among
the crawls, and will let us evaluate strategies for combining
and linking resources.
Challenge: Preserving Resources.
The WAC preserves past Web states, but who preserves the
WAC content itself? In other words, WAC resources
stored at member archives can be lost due to
hardware failures or the member archive going out of business.
Resources can be preserved through replication, but
(a) member archives must be willing to store backup copies;
(b) the number of desired copies and their location must be determined, and
(c) update propagation mechanisms must be in place
to keep replicas synchronized.
The size and rate of change of WAC resources make
all these aspects especially challenging.
-
Thrust 4 (Preservation)
We will explore storage trading schemes that allow members
to trade local backup space for remote space.
We will extend the notion of self-preserving objects
to develop a Web archive replication tool.
We will study alternatives for replica synchronization.
For example, is it best to have a single crawler generate
one Web archive that is replicated at two other sites,
or is it better to have three coordinated crawlers that
each create their own archive of the same target sites?
Challenge: Filling the Gaps.
As we conduct our research, we are bound to see gaps in coverage:
data sets that researchers need but are not available anywhere,
or tools that researchers need but have not been developed.
Gaps occur when resources exist but are not shared
(e.g., query logs are often considered sensitive),
or for emerging applications where data collection
tools have not been developed
(e.g., the next Facebook or Twitter-like system).
-
Thrust 5 (Filling Gaps):We will study ways to fill the gaps. For example, it is
possible to gather query logs in a distributed fashion by using the
referrer field of HTTP requests from search engines. Thus, a
community of Web sites can gather a query log, filling an important
gap that exists today. We will also build data gathering tools for
emerging applications (e.g., an archive of Tweeter feeds and
profiles). Another gap exists for what is called the Deep
Web, i.e., information that resides in
backend databases but is displayed through dynamic Web pages. Such
information is very valuable but is hard to find in open Web archives
In addition to filling information gaps, we will also address gaps in
tools that facilitate archiving and resource sharing. For example, we
will adapt annoymization techniques explored by the security community
to the context of Web content, thus making owners more willing to
share their resources.
Challenge: Community Building.
The success of a WAC will depend on the willingness of members
to gather, implement, and share resources.
In turn, this willingness will depend on
the availability of useful standards and tools,
on the initial seeding of the WAC with a substantial
number of resources, and an understanding
of the legal and social issues related to research
of shared Web resources.
-
Thrust 6 (Community Building)
We will organize a number of workshops to bring together
key Web Science researchers, to discuss available resources
and impediments to sharing.
These workshops will drive our research,
identifying needed tools and protocols.
With small groups of participants, we will
establish challenge problems to attack,
e.g., combining a set of Web archives.
With restricted participation, we expect
to get access to more resources, demonstrating
that a collective effort can yield benefits to all.
Reports of these results at future workshops
can incentivize others to participate in the WAC.
In addition, we will set up an Advisory Board
of industrial, government, and academic experts
to guide our project.
Challenge: Education.
To keep Web Science vibrant, future researchers and practitioners need
to be trained.
However, current knowledge
(e.g., how to effectively run massive Web crawls,
how to extract meaningful information from massive Web data sets)
is widely dispersed, and current tools are poorly documented.
-
Thrust 7 (Education)
We will run a Summer Institute for Web Science graduate students.
At this Institute, students will learn to use the latest tools,
and will learn from each other's experiences in dealing with Web data.
In addition, we will develop a one-day workshop which can be offered
at Web Science conferences (WWW, SIGIR, etc.) to educate participants
about the resource made available by the WAC. We will also develop
an undergraduate Web Sciences track for computer science majors that
will use WAC tools.
Project Advisory Board
Rakesh.Agrawal@microsoft.com
Martha Anderson, LOC
Pamela Anderson, Berkeley
Christine Borgman UCLA
Patricia Cruse, Cal. Digital Library
Richard Furuta Texas A&M
Alon Halevy, Google
Carl Lagoze, Cornell
Gary Marchionini, U.North Carolina
Raghu Ramakrishnan, Yahoo
Herbert van de Sompel, LANL
Appendices
Auxiliary Information from Kickoff Meeting
From Alex Thurman
Web Collection Curator
Columbia University Libraries
535 W. 114th Street
New York, NY 10027
at2186@columbia.edu
Here are some links to resources mentioned during the Workshop.
Columbia is currently surveying three user groups to help guide the design of our web archives access portal. The groups are: human rights researchers (students, faculty); content providers (NGOs whose sites we're archiving); and librarians/archivists. The surveys vary slightly for the 3 different groups, but are largely identical. If you'd like to see and/or complete the survey sent to librarians/archivists, the link follows. When we have our results I can share them with this group if desired.
Take the survey: http://www.surveymonkey.com/s/columbiawebarchives_L
More detailed web archives user studies are available from the Portuguese Web Archive at:
http://sobre.arquivo.pt/about-the-archive/publications
The results of the survey of web archiving initiatives that they conducted and posted on Wikipedia is at:
http://en.wikipedia.org/wiki/List_of_Web_Archiving_Initiatives
Two access portals that came up in discussion were the UK Web Archive and Trove
Directory of Existing Archives
As a first order of business we compiled a list of the Web archives that we are aware of. This list is available as a Google Docs spreadsheet. We invite the public to add entries for other archives as they become available. The current list comprises over 1500 entries.
JCDL Archiving Workshop
In the context of the Joint Conference on Digital Libraries (JCDL 2011) this project will
organize a workshop. The meeting will bring together interested parties from major archives, government, private, and academic. We will report on results.
Software Releases
We are working with the distributed computing infrastructure Hadoop. The goal is seamlessly to stream our WebBase archive through a compute cluster for analysis and processing. In this context we contributed an Excel load and store module to the Apache Pig open source project.
Data Access
Please visit our
WebBase archive, where we make several years of archived Web content available.





 .
.









 Children as well as adults grew deeply involved in programming a large
robot to gesture and dance. One of the WAC members wrote the prototype
for the underlying software (under separate funding). The system was
exhibited on six consecutive weekends at the museum, with help from us
volunteers. The age range of those attracted to the exhibit, and truly
engrossed in it was from 2 years to full adulthood, an astounding
spread.
Children as well as adults grew deeply involved in programming a large
robot to gesture and dance. One of the WAC members wrote the prototype
for the underlying software (under separate funding). The system was
exhibited on six consecutive weekends at the museum, with help from us
volunteers. The age range of those attracted to the exhibit, and truly
engrossed in it was from 2 years to full adulthood, an astounding
spread.