Figure 1: The IMI reference model
Database Group,
Stanford
University
{melnik,stefan}@db.stanford.edu
Keywords: modeling, interoperability, object layer
Current software agents extract information from webpages using wrappers [SaA99]. Wrappers are site-specific software modules that extract information based on the regular structure of webpages. But wrappers are expensive to built and difficult to maintain, since they require manual work, and an automated agent can not access information before a wrapper is (manually) created. Hence, the agent can not just browse the web on its own and explore and use the found information. This explains the current very limited capabilities of automated agents browsing the web: semantic interoperability on the web is currently very limited. To really facilitate automated agents on the web, agent-interpretable formal data is required. However, it is not immediately clear what kind of data and and what tools are necessary to support creating and deploying agent interpretable data.
A number of standards and efforts are targeted at populating the Web
with machine-processable information. Tim Berners-Lee coined the term "Semantic
Web" to refer to this new, richer Web, in which automated agents can help
humans more effectively with achieving their tasks.
The machine-oriented web will contain much like the HTML-oriented
web today vastly diverse information. Even a human Web user nowadays
will find a lot of information contained on the Web incomprehensible (eg.
a psychologist confronted with details of quantum mechanics, or a lawyer
looking at a page on molecular biology). Similarly, we can hardly expect
that an automated agent will a priori be able to "understand" all information
available on the Web.
If needed, however, a human being can figure out the meaning of the terms used by other people, and make use of the previously incomprehensible information. Automated agents need a similar capability. Humans could then delegate to them a lot of boring and time-consuming tasks like finding an inexpensive flight, filing a tax return, or locating an electronic version of someone's publication. The lack of "common understanding" is a major obstacle on the way to building the Semantic Web. Various representation technologies have been developed that allow capturing information in machine-processable manner. However, applications that deploy different information models often cannot interoperate effectively. Establishing interoperation is a complex task, with lots of special-case solutions. Solving the interopability problem on a broad scale, as required for an agent-enhanced web, requires a novel approach.
One of the most urgent needs is the reduction of the complexity of the problem. A common strategy for complexity reduction is the identification of abstraction layers, which hide the complexity of the levels below them and make problems manageable. A layered approach to the Semantic Web and a set of common interfaces and tools to specific layers enables replacing a concrete realization of one layer with another realization of that layer (comparable to exchanging the physical layer in a TCP/IP network, e.g. exchanging a token ring by Ethernet). Such a layered approach would enable setting up agents-based services on top of existing services, and reusing the tools developed for the lower layers. This paper suggests such a set of layers, which provide the necessary abstractions for managing the complexity of interoperability on the Semantic Web.
The rest of the paper is organized as follows. In the next section, we briefly introduce several modeling languages used for illustration throughout the paper. Then we give a motivating example. In Section [4] we describe a reference model that we use to structure disparate Web-enabled information models. After that, we discuss the features and implementation of the object layer in more detail. In Section [6] we will revisit our motivating example and demonstrate the benefits of using an intermediate object layer.
Remarkably, RDF, UML, and SHOE have XML-based serializations. Unfortunately, the praised lingua franca of the Web offers only limited help in building a bridge between the modeling approaches used in our example, even if we assume that we have global identifiers for the concepts "food" (e.g. urn:cyc:food:Food) and "edible stuff" (e.g. urn:cyc:food:EdibleStuff). The serialization of the assertion that "food is edible stuff" can be represented in the XML-based syntax for RDF as follows:
R1:
<Class rdf:ID="urn:cyc:food:Food">
<subClassOf>
<Class rdf:ID="urn:cyc:food:EdibleStuff"/>
</subClassOf>
</Class>
In XMI, the XML-based serialization standard for UML, the same fact looks rather like:
U1:
<Foundation.Core.Generalization>
<Foundation.Core.Generalization.child>
<Foundation.Core.Class
xmi.uuid="urn:cyc:food:Food"/>
</Foundation.Core.Generalization.child>
<Foundation.Core.Generalization.parent>
<Foundation.Core.Class
xmi.uuid="urn:cyc:food:EdibleStuff"/>
</Foundation.Core.Generalization.parent>
</Foundation.Core.Generalization>
Finally, in the XML syntax of SHOE, our relationship between food and edible stuff is represented as follows:
S1:
<DEF-CATEGORY NAME="urn:cyc:food:Food"/>
<DEF-CATEGORY NAME="urn:cyc:food:EdibleStuff"
ISA="urn:cyc:food:Food"/>
Unsurprisingly, all three XML serializations look absolutely distinct. XML is a very flexible language fostering the creativity of independent developers. The current state-of-the-art of translating between the above XML serializations is to use a declarative transformation language like XSLT [XSLT]. For brevity, we do not present an XSLT specification for our example (in fact, it is by no means compact). Instead, we notice that one such specification would not solve our integration problem. The complicating fact is that the syntaxes for RDF and UML allow various representations for the same state of affairs. An alternative serialization in RDF that is semantically equivalent to R1 looks like
R2:
<rdf:Description rdf:ID="urn:cyc:food:Food">
<subClassOf rdf:resource="urn:cyc:food:EdibleStuff"/>
<rdf:type rdf:resource="http://www.w3.org/TR/1999/PR-rdf-schema-19990303#Class"/>
</rdf:Description>
<Class rdf:ID="urn:cyc:food:EdibleStuff"/>
The XMI serialization for our example could equally well be
U2:
<Foundation.Core.Class xml.uuid="urn:cyc:food:Food">
<Foundation.Core.GeneralizableElement.generalization>
<Foundation.Core.Generalization
xmi.idref="S.00001"/>
</Foundation.Core.Generalization.generalization>
</Foundation.Core.Class>
<Foundation.Core.Class xml.uuid="urn:cyc:food:EdibleStuff">
<Foundation.Core.GeneralizableElement.specialization>
<Foundation.Core.Generalization
xml.idref="S.00001"/>
</Foundation.Core.Generalization.specialization>
</Foundation.Core.Class>
<Foundation.Core.Generalization xmi.id="S.00001"/>
A variety of further valid syntactic alternatives is conceivable. In order to account for all possible syntactic forms, we would have to write a number of long and elaborate XSTL specifications. Thus, the translation task becomes very laborious, if not prohibitive.
The reason for this complexity is the gap of abstraction between object-oriented approaches used in information models like RDF, UML, or SHOE, and the low-level document model provided by XML. Similar gaps of abstraction can be observed in other areas, e.g. compiler technology or internetworking. Compilers for programming languages often use intermediate languages to cope with the complexity of the compilation task and to simplify optimization. Large-scale networks like the Internet are built using protocol hierarchies to reduce the complexity of communication.
In our example, the gap of abstraction emerges when we try to integrate information on the conceptual level using syntactic primitives. To bridge this gap we suggest using an intermediate modeling layer that we call the object layer. In the next section we describe a reference model that we use to structure disparate Web-enabled information models. After that, we discuss the features and implementation of the object layer in more detail. In Section [6] we will revisit our motivating example and demonstrate the benefits of using an intermediate object layer.
Figure 1: The IMI reference model
The syntax layer is responsible for representing structured information as byte streams. The basic function of the object layer, or frame layer, is to provide applications with an object-oriented view of their domain. The semantic layer, or knowledge representation layer, deals with conceptual modeling and knowledge engineering tasks. In the rest of this section, we briefly describe each of the layers in a bottom-up fashion, and examine the advantages of the layered approach to information modeling.
Any application that exchanges information with other applications or stores it persistently needs to structure the information carefully so that the recipient or reader can retrieve the information in its original form. Data structures used by applications are typically not just flat lists of uniform data elements. Therefore, additional markup mechanisms are required to preserve the nested structure of the data. XML tagging or ASN.1 encoding rules are examples of such markup mechanisms. The syntax layer can typically be divided into three sublayers (bottom-up):
The IMI reference model that we suggest borrows heavily from the Open Systems Interconnection (OSI) model used in the internetworking. In OSI, the service definition tells what the layer does, not how entities above it access it or how the layers works. Just as the physical layer in OSI is concerned with transmitting raw bits over a communication channel, the service offered by the syntax layer in IMI consists in marshalling and manipulation of nested data structures. A layer's interface tells the applications above it how to access it. It specifies what the parameters are and what results to expect. Broadly accepted interfaces for the syntax layer are XML DOM and SAX. The interface says nothing about how the layer works inside. The peer protocols used in an OSI networking layer are the layer's own business. Similarly, the implementations of a layer in IMI can differ. It can use any implementation it wants to, as long as it gets the job done (i.e., provides the offered services like serialization or n-ary relationships).
Thus, one of the major criteria for splitting an information model into layers is whether it is possible to define a clean interface between the layers. Some of these interfaces are already in place, like DOM for the syntax layer or the UML CORBAfacility for the object layer. We merged all features that cannot always be separated in a well-defined manner into a single layer. These distinctive features form sublayers. For example, in the object layer, sometimes ordering may use reification, and sometimes it can be built on top of n-ary relationships. Thus, there can exist mutual dependencies between sublayers in different information models.
To summarize, layering representation languages has the following advantages:
In the discussion of the object layer we are again following a bottom-up approch, i.e. from the ground-level features to more high-level ones. The design issues that we consider in this section have a logical character. They do not necessarily preclude the variety of implementation alternatives at the programming level. Nevertheless, a logical implementation can have major impact on the API design. In Section [5] we examine some programming-level implementation issues.
As long as an application does not need to exchange information with other applications, is does not matter how the objects are identified. In fact, suitable object-oriented APIs may hide the object identity from the programmer completely. To take advantage of the Semantic Web, applications need to communicate, either directly or indirectly by publishing information in machine-readable form. Thus, explicit identifiers for the objects are required. In RDF, objects are identified using the Uniform Resource Identifiers (URIs), a generalized form of Uniform Resource Locators (URLs). A similar approach is taken by SHOE. In UML, objects are identified using Universally Unique Identifiers (UUIDs). OEM allows any unique variable length identifiers. URIs, UUIDs etc. support global identity for the objects, which is a prerequisite for building the Semantic Web.
Information models use different abstract notations for binary relationships between objects. In this paper, we adopt the RDF notation. Figure [2] illustrates a binary relationship between a source and a destination object. As a rule, the position of the object in a relationship, i.e. source or destination, is significant. In RDF, every such relationship is viewed as a statement, or assertion. The source and destination objects are the subject and the object of the assertion, respectively.
Figure 2: Abstract notation for a binary link between two objects
In UML, relationships between object instances as shown in the figure are referred to as links. The relationship types, i.e. the relationship as a whole in the semantic layer, is called association. To avoid ambiguity, we follow this terminology.
In OEM, basic typing is used to denote atomic types such as integer or string, and container types such as set or list. Since the "types" themselves are first-class objects, the application can request additional information about the types.
In RDF, the purpose of basic typing is to allow bootstrapping of more complex typing facilities in the semantic layer. In the notation used above, basic typing of an object A using object B is represented as an arc from A to B with a label like type that denotes basic typing.
Reification of links and associations is illustrated in Figure [3]. The big oval denotes the object that represents the reified link. In the figure, this object is used as the source for another link. To emphasize reification of the association in the bottom part of the figure, the association is circumscribed as an object. This object can, too, participate in other links. These two kinds of reification provide the necessary prerequisites for computational reflection, i.e. the capability for a computational process to reason about itself [Smi96].
Figure 3: Reification of links and relationships
Both UML and RDF support reification of links and associations. In both standards, link reification is logically implemented by introducing a new object with properties that identify the parts of the link. The logical implementation of link reification in RDF is illustrated in Figure [4].
Figure 4: Logical implementation of reified links in RDF
Figure [5] illustrates five logical implementation alternatives for the ordered binary relationship between "Requiem" and the two composers. The right-hand size of the figure presents a "logical" view of the object graphs. The five alternatives are named specialization, container, ordinal properties, ternary, and reification, according to their logical implementation. Notice that although any representation can be bijectively translated into every other one, they are more or less semantically faithful. For example, the second representation (container) is particularly semantically misleading for representing ordered relationships since it states that the creator of "Requiem" is an object typed as Sequence.
Figure 5: Implementation alternatives for ordered relationships
A qualitative comparison of the alternatives is presented in Table [1]. Besides semantic faithfulness, we consider how difficult it is to use the same logical schema for representing the inverse order. Inverse order is required when the objects at the source end that are related to a single object at the destination end have an ordering that must be preserved. For example, if the "creator" association were to capture the chronological order of the pieces written by the composers, representation for the inverse order would be needed. We gave a minus (-) to the schemes that required creation of additional reified objects for links or associations to support inverse order.
| Alternative | Semantic faithfulness | Inverse order | Implementation effort |
| specialization | ++ | - | -- |
| container | -- | - | -- |
| ordinal properties | +- | - | - |
| ternary | +- | + | +- |
| reification | + | + | + |
Table 1: Logical implementation alternatives for ordering
Finally, the last metric that we consider here is the implementation effort. By implementation effort we mean not the effort needed to implement the API that allows manipulating ordered relationships, but the effort needed to use such an API. The typical operations we considered are
In some information and data models, ordering is built-in, i.e. it cannot be reduced to other modeling primitives like reification and binary relationships. Such models include UML, OEM, and XML. In other models like RDF and SHOE, ordering is not a built-in feature and can be implemented in various ways, similarly to the alternatives that we considered above. The choice of alternatives depends on the availability of modeling primitives. For example, since SHOE lacks reification, ordering by reification is out of the question.
Often, n-ary relationships are logically implemented on top of the four sublayers discussed above. Nevertheless, a clear definition of the semantics of n-ary relationships is crucial for interoperability between information models. n-ary relationships cannot be implemented as a combination of binary relationships without using additional objects. Thus, in the object layer, an n-ary link is typically represented as an object that is linked to n objects participating in the link (see Figure 6).
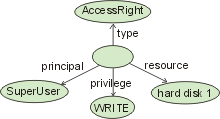
Figure 6: Example of a ternary link
Notice that the logical implementation depicted in the figure does not impose a specific implementation on the programming level. For example, the above ternary link can be implemented as a 3-tuple in a relational database. Using n-ary relationships, however, requires specifically designed API methods.
Some features in the table are marked as implicit. These features, like ordering in UML or n-ary relationships in SHOE, are visible on the API level only. They are not directly represented in the object model.
| Feature | RDF | UML | SHOE | OEM | OIL |
| object identity and binary relationships | + | + | + | + | + |
| basic typing | + | + (implicit) | + (implicit) | + | + |
| reification | + | + | 0 | 0 | 0 |
| ordering | 0* | + (implicit) | 0 | 0* | 0 |
| n-ary relationships | 0 | + | + (implicit) | 0 | 0 |
Table 2: Object layer features in RDF, UML, SHOE, OEM and OIL
*: RDF containers and OEM lists do not carry the semantics of ordered relationships
To illustrate the importance of the design of the object layer, consider the following implementation of ordering using a relational DBMS. In this implementation, a single table tuples holds binary links between objects in a generic fashion. The table contains four fields, all of the same type, that represent object identifiers (Object identifiers in a database system are typically implemented as integers. In the examples below we are using stylizised string values). The implementation uses order by reification. A sample content of the database is shown below.
ID S
P O
--------------------------------
id1 Requiem creator
Salieri
id2 Requiem creator
Mozart
id3 id1
order 2
id4 id2
order 1
id5 Pinocchio creator Geppetto
The table contains two ordered links and one unordered link. The field ID contains identifiers of reified links. All find-queries listed in Section [4.4] as implementation criteria can be executed using a single SQL query. The most sophisticated query of these is retrieving the first creator. The complicating factor is that some creators are unordered. Still, retrieving the first creator for an object like Requiem can be done using the following single query:
SELECT s1.S, s1.O
FROM tuples AS t1 LEFT JOIN tuples
AS t2 ON t1.ID=t2.S
WHERE t1.S=Requiem AND
t1.P=creator
AND
(t2.P IS
NULL OR t2.P=order) AND
(t2.O IS
NULL OR t2.O=1)
GROUP BY s1.S
The GROUP BY clause is required to reduce the number of multiple unordered creators to one. The first creators of all objects can be retrieved by dropping the first conjunct in the WHERE clause. The result of the query would be:
(Requiem, Mozart)
(Pinocchio, Geppetto)
<tuple ID="id1" S="Requiem" P="creator" O="Mozart"/>
<tuple SID="id1" P="order" O="1"/>
The XML attribute SID in the second tuple is a reference to an ID attribute declared in the first tuple. For even more compact representation, a specialized ordering syntax can be used. Thus, the fact that Salieri is the second creator can be serialized as:
<tuple S="Requiem" P="creator" O="Salieri" order="2"/>
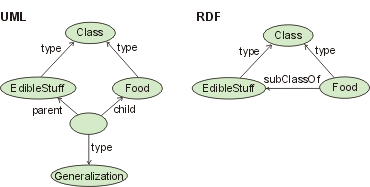
Figure 7: "food is edible stuff" at the object layer
Instead of using complex XSLT transformation, the translation from UML to the RDF representation can be achieved using a rule like
(X subClassOf Y) <= (Z type Generalization), (Z child X), (Z parent Y)
In our approach to structuring the Information Model Interoperability (IMI) reference model we are building on the analogy with the Open Systems Interconnection (OSI) reference model used in computer networks [Tan97]. One of the major contributions of OSI is to provide a clear distinction between services, interfaces and protocols used in internetworking, enabling a stack of services on top of the more basis levels.
Our analysis of the selected information models in this paper suggests that a comprehensive object layer is yet to be defined. RDF and OEM [PGMW95], which are completely contained within the object layer, lack support n-ary relationships. SHOE and RDF are lacking standard order semantics. Although UML supports most of the features that we discussed, it prohibits coexisting objects from different UML metalayers, i.e. it is not possible, for example, to establish a relationship between a class and an instance of this class.
We believe that achieving semantic interoperability on the Web using a single monolithic information model defining the capabilities of all layers is irrealistic. Multiple information models need to coexist and cooperate. In this respect, interoperability results like those described in [HeH00] are to be taken with a grain of salt, since they are based on the assumption that all agents and knowledge providers are using SHOE. SHOE is aimed at a specific knowledge representation task, and other KR systems, e.g. for describing dynamic or probabilistic information, will be definitely needed.
In this paper we make the following three contributions. First, we analyse some information models and suggest a layered reference model for Information Model Interoperability. The reference model allows reducing the complexity of achieving interoperability between information models on the Semantic Web. We identify the object layer and examine its features in detail. Finally, we discuss issues involved in implementation of the object layer. We believe that an agreement on a common object layer can be an important step toward the realization of the Semantic Web.
| BKD+00 | Jeen Broekstra, Michel Klein, Stefan Decker,
Dieter Fensel, and Ian Horrocks. Adding formal semantics to the Web:
building on top of RDF Schema. Technical Report: Free University of
Amsterdam, 2000,
http://www.ontoknowledge.org/oil/extending-rdfs.pdf |
| Bor85 | A. Borgida: Features Of Languages For The
Development Of Information Systems At The Conceptual Level. IEEE Software,
January 1985
ftp://ftp.cs.rutgers.edu/pub/borgida/CML-features.ps.gz |
| Bra79 | Ronald J. Brachman, On the Epistomological Status of Semantic Networks. In: Findler, Nicholas V. (Ed., 1979). Associative Networks. Representation and Use of Knowledge by Computers. New York: Academic Press, 1979:3-50. |
| BrG00 | Dan Brickley and R.V. Guha (eds). Resource
Description Framework (RDF) Schema Specification 1.0, 2000. W3C Candidate
Recommendation, 2000
http://www.w3.org/TR/2000/CR-rdf-schema-20000327/ |
| Cat91 | R. G. G. Cattell: Object Data Management. Addison-Wesley, 1991 |
| DSS93 | R. Davis, H. Shrobe, and P. Szolovits. What
is a Knowledge Representation? AI Magazine, 14(1):17-33, 1993
http://www.medg.lcs.mit.edu/ftp/psz/k-rep.html |
| FHH+00 | D. Fensel, I. Horrocks, F. Van Harmelen, S.
Decker, M. Erdmann, and M. Klein. OIL in a Nutshell In: Knowledge
Acquisition, Modeling, and Management, Proceedings of the European Knowledge
Acquisition Conference (EKAW-2000), R. Dieng et al. (eds.), Lecture Notes
in Artificial Intelligence, LNAI, Springer-Verlag, October 2000.
http://www.cs.vu.nl/~ontoknow/oil/downl/oilnutshell.pdf |
| GeK94 | M. R. Genesereth and S.P. Ketchpel: Software Agents In: Communications of the ACM 37(7, July), 48-53, 1994 |
| GHW99 | R. Goldman, J. McHugh, and J. Widom. From
Semistructured Data to XML: Migrating the Lore Data Model and Query Language.
WebDB Workshop, 1999
http://dbpubs.stanford.edu/pub/1999-53 |
| HHL99 | J. Heflin, J. Hendler, and S. Luke. SHOE:
A Knowledge Representation Language for Internet Applications.Technical
Report CS-TR-4078 (UMIACS TR-99-71), 1999
http://www.cs.umd.edu/projects/plus/SHOE/pubs/#tr99 |
| HeH00 | Jeff Heflin and James Hendler. Semantic Interoperability
on the Web.In Proceedings of Extreme Markup Languages 2000. 2000
http://www.cs.umd.edu/projects/plus/SHOE/pubs/#extreme00 |
| HFB+00 | I. Horrocks, D. Fensel, J. Broekstra, S. Decker,
M. Erdmann, C. Goble, F. van Harmelen, M. Klein, S. Staab, R. Studer, and
E. Motta The Ontology Inference Layer OIL, Technical Report, Free
University of Asterdam, 2000,
http://www.cs.vu.nl/~dieter/oil/Tr/oil.pdf |
| LaS99 | Ora Lassila and Ralph R. Swick (eds). Resource
Description Framework (RDF) Model and Syntax Specification. W3C Recommendation,
1999
http://www.w3.org/TR/REC-rdf-syntax/ |
| Mel99 | S. Melnik: An API for RDF, 1999
http://www-db.stanford.edu/~melnik/rdf/api.html |
| Mel00 | S. Melnik: Representing UML in RDF, 2000
http://www-db.stanford.edu/~melnik/rdf/uml/ |
| PGMW95 | Y. Papakonstantinou, H. Garcia-Molina, J. Widom:
Object
Exchange Across Heterogeneous Information Sources Proc. Int. Conf.
on Data Engineering (ICDE), 1995
http://dbpubs.stanford.edu/pub/1995-6 |
| RDF | W3C: Resource Description Framework
http://www.w3.org/RDF/ |
| SaA99 | A. Sahuguet and Fabien Azavant. Building light-weight wrappers for legacy Web data-sources using W4FIn: International Conference on Very Large Databases (VLDB99) 1999. |
| Smi96 | Brian C. Smith: On the Origin of Objects. MIT Press, 1996 |
| Sow00 | John F. Sowa. Ontology, Metadata, and Semiotics.
Proc. Int. Conf. on Conceptual Structures (ICCS), Aug 2000
http://www.bestweb.net/~sowa/peirce/ontometa.htm |
| Tan97 | Andrew. S. Tanenbaum. Computer Networks, Prentice-Hall, 3rd ed., 1997 |
| XSLT | W3C: XSL Transformations (XSLT), W3C
Recommendation, 1999
http://www.w3.org/TR/xslt |