4.1 Datatypes in a model-theoretic interpretation
A datatype mapping is considered to be a binary relational extension that exists in a model-theoretic interpretation. Both the value space of the datatype and its lexical space are subsets of the universe used in the interpretation.
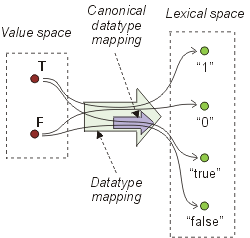
(@@@ this document does not describe what the extensions of datatypes themselves are in
a model-theoretic interpretation.)
The elements of value spaces can be "named" explicitly using
URI references. For example, a resource with URI reference
like xsd:boolean.value.T could be used to denote the
element T of the value space of xsd:boolean.
This document does not suggest any such explicit identifiers for
the elements of value spaces.
[XSD] specifies a unique
URI reference for each built-in datatype that is defines.
For example, the URI
This document proposes that the identifiers for the lexical spaces, value spaces, datatype mappings
and canonical datatype mappings be constructed following the above principle.
For example:
This document proposes a fixed interpretation of resources with URI references
like the ones listed above that correspond to the following
XSD datatypes:
(@@@ do we need all those XML-specific types like IDREF?)
In this document, the shortcut "xsd:" is used to abbreviate the
namespace http://www.w3.org/2001/XMLSchema#.
As illustrated in [XSD] (Sec. 3),
the datatype mappings of the derived types can be arranged in a hierarchy.
For example, type int is derived (by restriction) from long,
which is derived from integer, which is derived from decimal, which is a primitive type.
[Definition:]
Datatype B is derived by restriction from datatype A,
if and only if the datatype mapping of B
is contained as a subset in the datatype mapping of A.
The built-in derived types of [XSD] satisfy the above definition.
A new derived type can be obtained by restricting the lexical space of a datatype.
In this case, the datatype mapping of the new type is a range-restricted
datatype mapping of the source type.
Notice that according to [RDF MT],
properties
rdfs:domain and rdfs:range define
a subset relationship between the range of a property
extension and the corresponding class extension. In other words,
rdfs:domain and rdfs:range alone
are not sufficient to define precisely the
interpretations of xsd:decimal.lex and xsd:decimal.val given
an axiomatic definition of xsd:decimal.map.
Frequently, interpretations of literals belong to lexical spaces of several datatypes.
For example, the interpretation I("10") of literal "10" is both an element of
the lexical space of xsd:string and the element of the lexical space of
xsd:integer.
In Idiom B, schema information (e.g., specified using [RDF Schema])
provides a hint for the validation and usage of the literals.
Use of Idiom B is akin to type handling in programming languages like Perl.
In this perspective, literals correspond to scalars, which
are typecast depending on the input/output type of operations
(see [PL] for a detailed discussion).
Use of Idiom A is advantageous for evolving applications, especially those
that need to interoperate with other applications. Idiom A supports
multiple lexical representations for a given data value
in an RDF graph. This feature facilitates migration and parallel use
of alternative lexical representations (e.g., encoding "2001-07-15" can supercede
"July 15, 2001" without breaking the existing applications).
Another feature of Idiom A is enforcement of local typing, i.e.,
the typing information always accompanies the data instances in RDF graphs.
This feature makes data instances more robust with respect to incompatible changes
in schemas.
This section defines a unit system and illustrates its use in the "S" scheme.
Just like lexical tokens
are mapped to typed values using datatype mappings, numbers are mapped
to values of measure using unit mappings.
[Definition:]
A unit type is a 3-tuple, consisting of a) a set of distinct values,
called its measure space, b) a set of numbers, called its numeric space, and
c) a one-to-one mapping between the numeric space and the measure space called its
unit mapping.
(@@@ what organizations standardize measures? NIST, ISO, DIN? Should we define
vocabulary for the Metric system? This could be a proper contribution of this document ;-)
(@@@ what needs to be explained? What Ntriples, RDF/XML etc. examples need to be provided?
Should the different idioms be illustrated using the above example?)
4.2 Representation of datatype mappings
A datatype mapping can be "named" using
RDF properties. In this document, such properties are referred to as
datatype properties. To associate a datatype property with a certain datatype,
the extension of the datatype property is defined to be the datatype mapping that belongs
to the datatype.
4.3 Representation of value spaces and lexical spaces
Since value spaces and lexical spaces are subsets of the elements in the universe, they
can viewed as class extensions and can be referred to in RDF graphs by means of
resources that identify classes.
CEXT(I(xsd:boolean.val)) := {T, F}
4.4 Representation of elements of value spaces and lexical spaces
In RDF graphs, literals can be used to refer to the elements of the
lexical spaces of datatypes.
Using a combination of datatype properties and literals, it is possible to
refer to data values of datatypes.
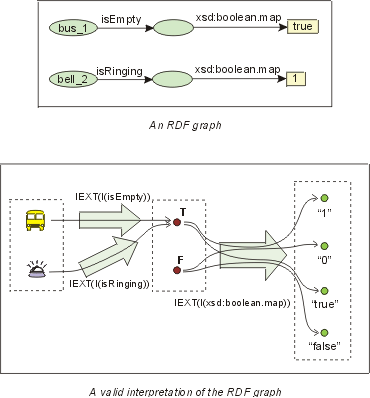
4.5 XML Schema datatypes
This section explains how built-in atomic XML Schema datatypes can be used
in the datatyping scheme "S". Non-atomic types (like IDREFS) are out of scope of
this document.
is used to address the datatype int. [XSD] suggests that the
components of the datatypes (specifically, datatype facets) be addressed using
URIs constructed by appending "." and the name of the component to the URI
of the datatype.
4.6 Definition of datatypes
[XSD] discusses several
ways of defining datatypes (e.g., axiomatically, by enumeration, by restriction).
This document only considers axiomatic definitions of datatypes.
User-defined datatypes and dedicated vocabularies for datatype definition
are out of scope of this document.
4.7 Relating datatypes and their components
Schema languages like [RDF Schema] can be used
to relate different datatype components, e.g. datatype mappings and lexical spaces,
to each other. Explicit relationships between
datatype components help reduce the amount of built-in semantics that
needs to be hard-coded into applications.
xsd:decimal.map rdfs:range xsd:decimal.val
xsd:decimal.map rdfs:domain xsd:decimal.lex
xsd:integer.map rdfs:subPropertyOf xsd:decimal.map
xsd:long.map rdfs:subPropertyOf xsd:integer.map
xsd:int.map rdfs:subPropertyOf xsd:long.map
xsd:int.cmap rdfs:subPropertyOf xsd:int.map
xsd:integer.val rdfs:subClassOf xsd:decimal.val
xsd:long.val rdfs:subClassOf xsd:integer.val
xsd:int.val rdfs:subClassOf xsd:long.val
xsd:decimal.lex rdfs:subClassOf rdfs:Literal
xsd:integer.lex rdfs:subClassOf xsd:decimal.lex
xsd:long.lex rdfs:subClassOf xsd:integer.lex
xsd:int.lex rdfs:subClassOf xsd:long.lex
4.8 Discussion of selected datatypes
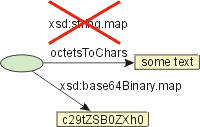
xsd:string
The datatype mapping of the datatype string is interpreted as an identity mapping.
xsd:base64Binary and xsd:hexBinary
The value space of xsd:base64Binary is equivalent to
the value space of xsd:hexBinary and is the set of
finite-length sequences of binary octets.
The value space of xsd:string are sequences of characters.
That is, xsd:base64Binary.val is disjoint from xsd:string.val.
4.9 Modeling styles
The "S" scheme supports two distinct ways of using typed values in RDF graphs, or
two different "idioms". This document does not prescribe which of the idioms
should be used in RDF applications. The following subsections illustrate and compare
these two idioms.
Idiom A ("advanced")
In Idiom A, the elements of value spaces of datatypes are used for
representing typed data elements.
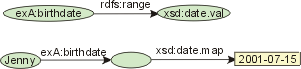
Idiom B ("backward compatible")
In Idiom B, the elements of lexical spaces of datatypes are used for
representing typed data elements.

Idiom A versus Idiom B
Many existing RDF applications deploy Idiom B. The major advantages of Idiom B
are backward compatibility and compactness. The fact that Idiom B utilizes
the elements of lexical spaces rather than the elements of value spaces is
unimportant for most applications.
4.10 Open issues
5 Unit System (@@@ likely out of scope)
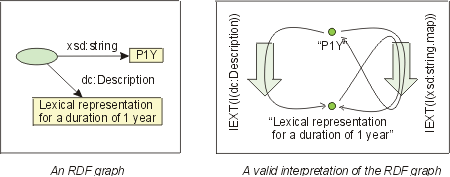
Measures like mass, duration, or monetary value are used in a variety of applications.
Measures are quite similar to datatypes. In fact, [XSD]
defines durations as datatypes, i.e., a lexical token like "P1Y" is mapped
to a duration of one year using a datatype mapping.
Many measures like mass, volume or monetary values are expressed
using quantities of units like kilograms, gallons, or US dollars.
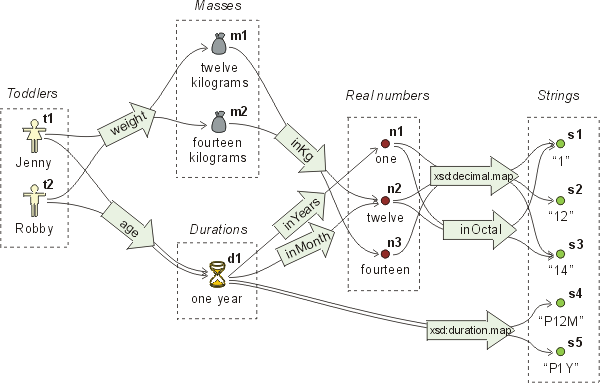
Graphs
Ntriple
_:Jenny age _:1
_:1 xsd:duration.map "P1Y"
_:Jenny weight _:2
_:2 inKg _:3
_:3 inOctal "14"
_:Robby age _:4
_:4 inYears _:5
_:5 xsd:decimal.map "1"
_:Robby weight _:6
_:6 inKg _:7
_:7 xsd:decimal.map "14"
RDF/XML
(@@@ is the encoding below correct. Dave?)
<rdf:Description>
<age xsd:duration.map="P1Y"/>
<weight rdf:parseType="Resource">
<inKg inOctal="14"/>
</weight>
</rdf:Description>
<rdf:Description>
<age rdf:parseType="Resource">
<inYears xsd:decimal.map="1"/>
</age>
<weight rdf:parseType="Resource">
<inKg xsd:decimal.map="14"/>
</weight>
</rdf:Description>
Datatyping scheme "P/P++"
(@@@ incomplete, removed for now)
Datatyping scheme "U"
(@@@ incomplete, removed for now)
References
Last modified: Fri Jan 18 11:25:15 PST 2002