Iconification
Omission
Across
elevations
(semantic zoom)
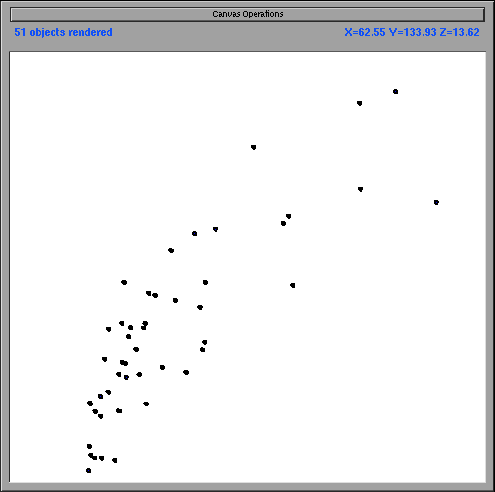
Figure 1a
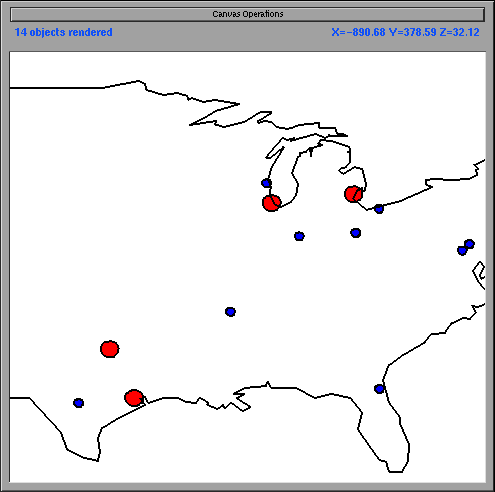
Figure 2a
At one elevation

Figure 1b
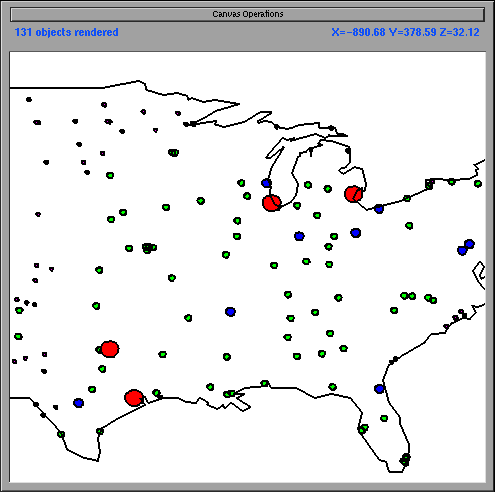
Figure 2b
Position paper
for the CHI '98 Workshop on Innovation and
Evaluation in Information Exploration Interfaces
(Los Angeles, April 1998)
Allison Woodruff and Chris Olston
Department of Electrical
Engineering and Computer Sciences
University of California, Berkeley
Berkeley, CA 94720
E-mail: {woodruff,cao}@cs.berkeley.edu
Because users find it difficult and unpleasant to explore cluttered displays, a number of visualization systems reduce clutter by allowing users to view detail selectively. Early work includes fisheye views and the Spatial Data Management System (SDMS) [2,3]. More recent paradigms include the Pad zoomable interface and Magic Lenses [4,1].
By its very nature, this strategy for clutter reduction eliminates certain details from the display. Two processes are common. First, a graphical representation may be iconified. Iconification is the process of transforming a graphical representation into a more compressed graphical representation. This compression may take a number of forms. For example, the graphical representation may change shape or detail may be omitted. Note that information may be lost during iconification. Consider a circle that represents a city. Suppose the radius of the circle is proportional to the population of the city. If the circle is iconified to a fixed-size dot, the data about the city's population is lost.
Second, data elements may be omitted, i.e., eliminated from the current view. In this case, all information about the omitted object is lost.
In general, the user can navigate to the information that has been removed, e.g., in semantic zoom systems an icon may change into a more detailed graphical representation when the user zooms in on it. However, in many cases the user may not be aware that a graphical representation has been iconified or omitted. This situation is particularly likely in information exploration tasks in which the user has only a vaguely defined goal. In these cases, the user may never discover certain information relevant to their task. We discuss the potential downfalls of iconification and omission in the next section of this paper. We then propose three techniques that (1) help the user become aware of the existence of detail of interest and/or (2) help the user navigate to this detail.
We consider iconification and omission in the context of semantic zoom systems. Such systems often represent data in a two-dimensional canvas over which the user can pan and zoom. The user's distance from the canvas is known as the user's elevation. In such systems, objects are iconified or omitted based on elevation. Therefore, the processes of iconification and omission are applied across elevations.
Figure 1a shows a visualization of census data. The x-axis represents housing cost and the y-axis represents income. Each state has two possible representations. The more detailed representation is a polygonal outline of the state. The iconified representation is a dot. Figure 1a shows a visualization in which iconification is applied across elevations. Specifically, at the current elevation all states are displayed as a dot. When the user zooms in on this visualization, the state outlines appear (not pictured).
Figure 2a shows a visualization of population data. Cities are categorized into four sizes. The two largest categories are drawn as larger circles; the two smaller categories are drawn as smaller circles. Figure 2a shows a visualization in which omission is applied across elevations. Specifically, at the current elevation only the two larger categories of cities appear. When the user zooms in, the smaller cities appear (not pictured).
Iconification and omission as applied across elevations do not visually cue the user that more information is available through zooming, nor do they provide the user information about how to navigate to that information. In the next sections, we propose three mechanisms for providing such cues.
Iconification |
Omission |
|
Across
elevations |
|
|
At one elevation |
|
|
Iconification is primarily difficult when the user does not have knowledge of the more detailed representations that are available, or when the user can not easily navigate to those representations. We have developed a new zoom method, goal-directed zoom, that addresses these problems. In semantic zoom systems, elevation implies representation. By contrast, in goal-directed zoom systems, representation implies elevation. In our implementation of goal-directed zoom [7], when the user selects an object in the canvas, the system presents a menu of graphical representations of the object. In this way, the system allows the user to preview more detailed representations for a given object, i.e., the user can learn about the iconification that has occurred. When the user chooses a representation, the system automatically pans and zooms until the representation chosen by the user appears in the display at appropriate visual detail. In this way, the system helps users navigate to detailed representations that are not visible at the user's current elevation.
Goal-directed zoom requires that the user make an explicit gesture to learn about potential representations. We have developed a system that presents different representations without any action being taken by the user. This system, VIDA (Visual Information Density Adjuster) [7], is based on the cartographic Principle of Constant Information Density [5]. VIDA iconifies or omits each object based on the density of the surrounding region at a given elevation. Therefore, objects in more dense areas are drawn with less detail and objects in more sparse areas are drawn with more detail.
Figure 1b shows VIDA's version of Figure 1a. In the dense regions, the states are displayed as dots; in the sparse regions, they are displayed as polygonal outlines. Therefore, different graphical representations are visible at a single elevation. (Note that combinations of iconification and omission at the same elevation and at different elevations are valid. For example, if more state outlines were added when the user zoomed in on the visualization in Figure 1b, as happens in VIDA, iconification would be present both at the same elevation and at different elevations.) Figure 2b shows VIDA's version of Figure 2a. In the densely populated areas, only the large cities are displayed. In the sparsely populated areas (those which contain no large cities), the smaller cities are displayed. Therefore, information is only omitted when necessary due to density.
VIDA's heterogeneous displays are complementary with goal-directed zoom. For example, if the user does not understand the relationship between the states and the dots in Figure 1b, they may invoke the goal-directed zoom menu and learn that one is a more detailed form of the other.
Omission can be fairly misleading. Consider Figure 2b. This visualization is consistent with the common cartographic convention of omission in paper maps (cartographic principles dictate that the amount of information per display area should remain constant [5], so different regions of a single paper map are displayed at different levels of detail). However, if this same technique were applied to a different type of visualization, e.g., a scatterplot, the user might incorrectly infer that no data existed in a specific region when in fact such data did exist.
Goal-directed zoom and heterogeneous displays do not alleviate this confusion. It is our belief that omission should be supplanted by some type of iconification whenever possible. In other words, the display should always contain some visual cue that objects have been removed from the display. We are particularly interested in cues that give specific detail about regions of the screen from which objects have been removed. For example, we might use a texture such as transparency or cloudiness to indicate the number of data points in a given subset of the display. Even if all objects were not displayed, the user could still infer the overall distribution from the texture. The user could then zoom in to areas of interest.
A specific example of this technique appears in [6]. In data mining applications, a common technique is to aggregate data. Analysts view the aggregations and drill-down into areas of interest. Typically they are particularly interested in detecting and investigating anomalies. However, high-level aggregates that appear to have no anomalies may in fact conceal exceptional values at a more detailed level. This can occur, for example, when anomalies in a more detailed level cancel each other out. Sarawagi et al. augment traditional displays with visual cues to indicate aggregates that contain exceptions. Their system interactively guides the user to these exceptions [6].