Independent Study Opportunities
with Andreas Paepcke

with Andreas Paepcke
Online Practice for Psychotherapists
Create an AI driven teaching environment for Psychotherapists
We have a Python framework for the textual portions of this system: a simple UI for therapist students, and communications with several LMMs. While work is still to be done in those areas, we need animated avatars of synthetic therapy patients. The avatars need to express emotions with their face, and muscle tension in their torso and limbs. They also need to speak the output of the LMMs.
Goal
We are constructing a training environment for psychotherapists. AI models generate synthetic patients with particular mental health challenges. Human therapist students must identify and respond to those underlying issues when confronted with AI generated patient statements. The system consists of both, AI generated text, and animated avatars that teach students about physical manifestations of mental states.

Animated avatar as synthetic therapy patient.
Soundscapes for Ecology Monitoring
Train algorithms to interpret audio recordings of eco systems.
We will train transformers to predict bat chirp characteristics, analogously to how chatbots are trained to predict next words, given the set of prior words.
Each chirp is characterized by about 110 physical measures, of which 35 explain 90% of chirp variance. The consequent dimensionality reduction may help us with this work.
We will test how well our predictions do, and hope to generate chirps that might make sense to bats; again, analogously to chatbots generating words.
While it would be difficult to observe bat reactions to synthesized chirps, we can embed our synthetic chirps, and see whether they cluster similarly to the naturally produced sounds.
We plan to use fluctuations in prediction confidence to detect possible edges of idiomatic chirp sequences.
Goal
Audio recordings of eco systems offer an inexpensive method for monitoring changes in the presence of animals, and annual environmental rhythms. In fact, groups of species are specialized to use particular parts of the audible and inaudible spectra. We focus on recordings of bat chirps, and try to predict the details of chirps, given their context. We also try to find edges of bat 'idioms'.

Envisioned architecture for analyzing bat chirps. Other options are wide open.
Teaching Choreography Online
A distributed system for teaching choreography remotely
We will try to use any appropriate distributed robotics simulator, such as Gazebo, to prototype an infrastructure that enables team-based teaching of choreography remotely. Choreography is not dancing. It is the design, the creation of dance steps that will then be danced by artists.
Using robotic creatures as artists would introduce new challenges into choreography. We could create modified gravity worlds, or animal artists with their non-human constraints. We would like target students to collaborate remotely through the infrastructure as they design dances together.
The infrastructure should also enable an instructor to monitor, and support students in their assignments.
Goal
We will develop infrastructure and (with help) pedagogy for teaching choreography entirely online. Choreography is the activity of designing dances. Geographically distant students will be able to work on dance design exercises together. The 'performers' will be avatars of any shape. They will operate in a 3D robotics simulation environment. Students will continuously be able to observe their teammates' work.

An online, collaborative choreography design infrastructure would provide freedom from constraints that limit choreographers for human artists.
Which Courses, and Why?
Explore what vector space embeddings of courses taken by students can reveal about pathways through college.
We will use historic enrollment, and possibly other data. Already available are vector embeddings from courses taken by past students. An exploration of the corresponding clusters is a first step. But we plan to generate a network of course sequences and their frequencies, to then apply network analytics to these structures. Our hope is to find course-taking patterns, and instances of unusual, innovative course choice behaviors.
A partially finished application based on Cytoscape was created by students, and there is plenty to do towards making that tool enormously useful (see bottom of figure).
Goal
If we understand how students make choices on their way through college, we can improve decision support for these important pathways. Courses chosen today have impact on other courses being options down the road, versus remaining closed for lack of prerequisite knowledge. Overly narrow course choices leave on the table important contributions that college can make to students' lives. A first goal is to understand what Stanford students have chosen over the past 18 years. That understanding can inform both future students, and university policy.
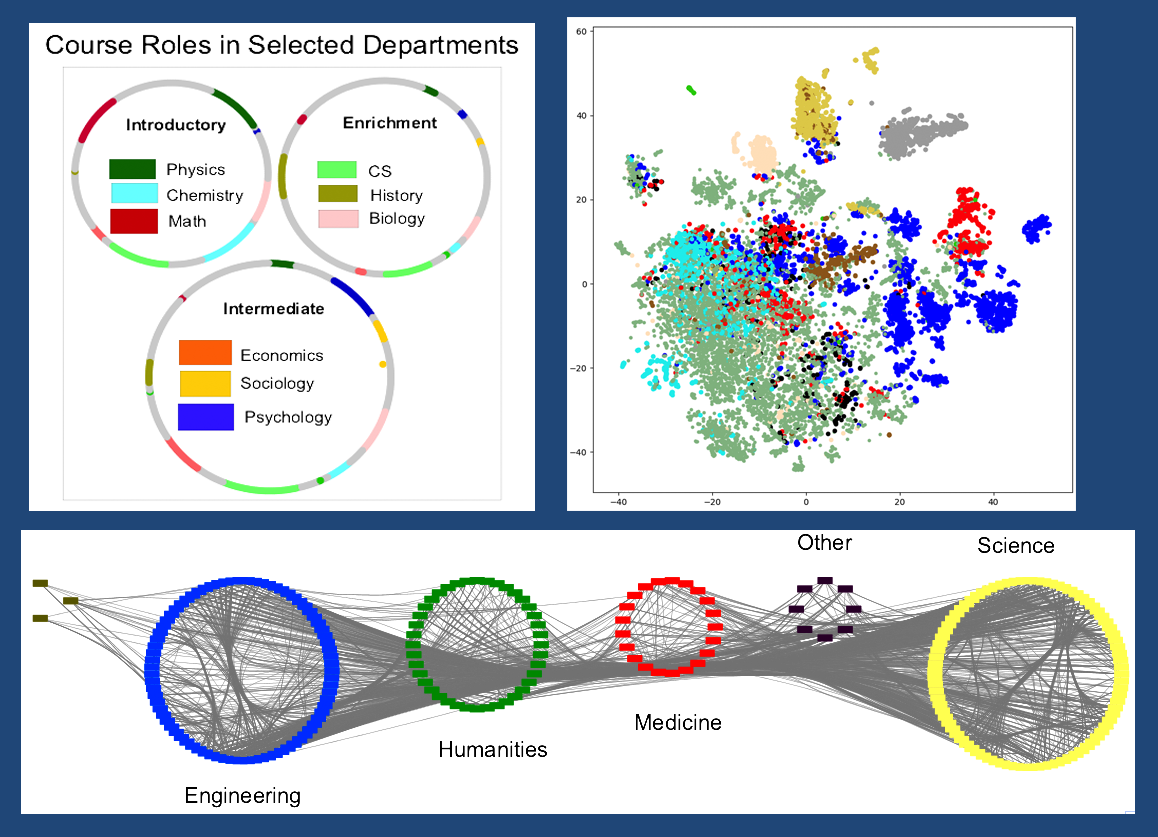
A number of novel charts derived from enrollment data.
The Gist of Course Evaluations
Deploy NLP on course evaluation answers to the question "What would you like to say about this course to a student who is considering taking it in the future?"
The first thought when thinking of applying NLP to opinions tends to be 'sentiment analysis.' We can of course run such techniques over evaluations, particularly because the domain of discourse is narrow: The content is always about Stanford courses. But more interesting will be the subtler gems. Hints such as "Definitely do the reading every week." Or "Problem sets are only every other week." Or "Find your project partner early, because you will need all the time you can get for completing the project." These hints will be harder to isolate, but could be extremely useful as a potential addition to Carta one day.
We have started this project; there is a code base, numbers to crunch, and several experiments to accomplish.
Goal
When students use Carta, they often glean information from the textual course evaluation part. We aim to extract salient course information from the text. If successful, the results of this work may migrate into Carta to help future students.

Determine top-10 of course reviews for some notion of 'top'
Predicting Sensitivity of Coral Reefs to Heat Stress
Analyze underwater photos of coral reefs to help learn their reaction to warming oceans.
An infrastructure has been contructed for labeling underwater photos that biologists have shot in the Pacific Ocean. We have labeled many photos, but a few more need to be done. After that effort, we are ready for machine learning. We are currently focusing on two coral guilds, aiming to train an algorithmic classifier. The central remaining work is that algorithm. If successful, our biology partners in the Hopkins Field Station will be able to transfer what they learn from their local corals to corals elsewhere in oceans.
Goal
An existing biology project is researching the impact of artificially introduced heat stress on coral bleaching. The 400 colonies under investigation are surrounded by sand, other types of corals, and algae. Given the heat stimuli and coral response data, can we create a predictor of coral response from photos taken around the corals? For example, can we help predict how surroundings of 25% sand, 30% branching corals, 35% encrusting algae, and 10% mounding corals predict coral response to heat?

The goal is to identify these species (guilds) of corals