Most previous work in change management has dealt only with flat-file
and relational data. For example, [LGM95] presents
algorithms for efficiently comparing sets of records that have keys.
The GNU diff utility compares flat text files by computing the
LCS![]() of their lines using the algorithm
described in [Mye86]. There are also a number of front-ends to
this standard diff program that display the results of
diff in a more comprehensible manner. (The ediff program
[Kif95] is a
good example.) However, since the standard diff program does
not understand the hierarchical structure of data, such utilities
suffer from certain inherent drawbacks. Given large data files with
several changes, diff often mismatches regions of data. (For
example, while comparing Latex files, an item is sometimes
matched to a section, a sentence is sometimes matched to a
Latex command, and so on.) Furthermore, these utilities do not
detect moves of data---moves are always reported as deletions and
insertions. Some commercial word processors have facilities for
comparing documents and marking changes. For example, Microsoft Word
has a ``revisions'' feature that can detect simple updates, inserts,
and deletes of text. It cannot detect moves. WordPerfect has a
``mark changes'' facility that can detect some move operations.
However, there are restrictions on how documents can be compared (on
either a word, phrase, sentence, or paragraph basis). Furthermore,
these approaches do not generalize to non-document data.
of their lines using the algorithm
described in [Mye86]. There are also a number of front-ends to
this standard diff program that display the results of
diff in a more comprehensible manner. (The ediff program
[Kif95] is a
good example.) However, since the standard diff program does
not understand the hierarchical structure of data, such utilities
suffer from certain inherent drawbacks. Given large data files with
several changes, diff often mismatches regions of data. (For
example, while comparing Latex files, an item is sometimes
matched to a section, a sentence is sometimes matched to a
Latex command, and so on.) Furthermore, these utilities do not
detect moves of data---moves are always reported as deletions and
insertions. Some commercial word processors have facilities for
comparing documents and marking changes. For example, Microsoft Word
has a ``revisions'' feature that can detect simple updates, inserts,
and deletes of text. It cannot detect moves. WordPerfect has a
``mark changes'' facility that can detect some move operations.
However, there are restrictions on how documents can be compared (on
either a word, phrase, sentence, or paragraph basis). Furthermore,
these approaches do not generalize to non-document data.
The general problem of finding the minimum cost edit distance between
ordered trees has been studied in [ZS89]. Compared to the
algorithm presented there, our algorithm is more restrictive in that
we make some assumptions about the nature of the data being
represented. Our algorithm always yields correct results, but if the
assumptions do not hold it may produce suboptimal results. Because
of our assumptions, we are able to design an algorithm with a lower
running-time complexity. In particular, our algorithm runs in time 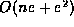 , where n is the number of tree leaves and e is the
``weighted edit distance'' (typically,
, where n is the number of tree leaves and e is the
``weighted edit distance'' (typically, 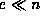 ). The algorithm in
[ZS89] runs in time
). The algorithm in
[ZS89] runs in time 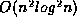 for balanced trees (even
higher for unbalanced trees).
for balanced trees (even
higher for unbalanced trees).![]() Our
work also uses a different set of edit operations than those used in
[ZS89]. The two sets of edit operations are equivalent in the
sense that any state reachable using one set is also reachable using
the other. A more detailed comparison of the two sets of edit operations
is in [CRGMW95].
Our
work also uses a different set of edit operations than those used in
[ZS89]. The two sets of edit operations are equivalent in the
sense that any state reachable using one set is also reachable using
the other. A more detailed comparison of the two sets of edit operations
is in [CRGMW95].
We believe our approach and that in [ZS89] are complementary; the choice of which algorithm to use depends on the domain characteristics. In an application where the amount of data is small (small tree structures), or where we are willing to spend more time (biochemical structures), the more thorough algorithm [ZS89] may be preferred. However, in applications with large amounts of data (object hierarchies, database dumps), or with strict running-time requirements, we would use our algorithm. The efficiency of our method is based on exploiting certain domain characteristics. Even in domains where these characteristics may not hold for all of the data, it may be preferable to get a quick, correct, but not guaranteed optimal, solution using our approach.