Introduction
There are data sources that are primarily intended for external access, such as public web pages, reports, bibliographies, etc. These are organized according to external access criteria. Since any resource has to be protected, access control for its perimeter is employed. Any external users are viewed as enemies until they are authenticated. Once authenticated, they are given access to the system. If some of the information is not intended to be public, then further security provisions are put into place that limit access to selected, authorized internal data. In the simplest case there are two classifications for the information, open and restricted. If there is variety of external customer types more classifications are added; the four mandatory layers that form the basis for military access control are well known. At the higher level a vertical, discretionary access control is imposed to create additional isolating cells. Combining mandatory and discretionary access rights increases the number the cells that have to be maintained, and the burden placed on data entry.
Today, security provisions for information systems focus on controlling access. At least five technological requirements interact in the process:
- Secure Communication
- Perimeter Control
- Reliable Authentication
- Authorization to information cells
- Partitioning of the information into cells
The first requirement is secure communication between the requestors and the information service, guarding against enemies and vandals [He:97]. The perimeter of the information system to be protected must be well-defined and controlled by a firewall [CheswickB:94]. There must be authentication, to assure that the person requesting information from that system is indeed the intended person [CastanoFMS:95]. Next there must be an authorization mapping from the authenticated person to the approved information cells [GriffithW:76]. Multi-level secure system methods may be needed when similar data can appear on distinct levels [KeefeTT:89]. Unfortunately, now the non-redundancy constraint that forms the basis for the relational database algebra is violated, increasing the complexity of obtaining reliable solutions [LuniewskiEa:93]. In object oriented-databases the mapping is more complex, because cross-references are embedded into the data structures [FernandezEA:94]. The fifth requirement, often under-emphasized, is that there must be a highly reliable categorization of all information to those cells [Oracle:99]. It is in the management of that categorization where many failures occur, and where collaborative requirements raise the greatest problem.
- Need to serve Collaboration
As businesses automate relationships beyond local, owned organizations, we find an increasing number of settings where external collaborators must be served by existing, internal information systems. There are needs for better response time, which are served by committing more communication to computer networks and interconnecting these networks. But information exchange with external systems also imposes security requirements that differ from those that are appropriate for intern users.
For instance, in manufacturing there is increased outsourcing of activities to external suppliers. Since the same supplier may serve one’s competitor, we must protect some of our information, while sharing up-to-date internal information to have an effective collaboration.
In military operations a prime examples is connecting Control and Command systems to logistics suppliers, who are often commercial, and maybe multinational corporations. Within the military there are intelligence distribution networks and tactical networks, currently isolated by having distinct staff assignments, as well as connections to allied forces. Even more challenging are novel and changing coalitions, sometimes with countries that might have been viewed as enemies not much earlier.
In the medical domain, the domain for our initial research focus, information must be made available to insurance companies and corporate payors, and at the same time patients’ privacy concerns demand that certain information be withheld. Tracking patients over time is important for researchers and healthcare improvement, but again, certain data must be kept private. Unfortunately, medical records contain so much ancillary information, that even when names and identifying numbers are suppressed, a modest amount of inferencing, using related, publicly available data, will reveal patients identities [Sweeney:97]. Current approaches to provide legal guidance are faltering in part due to the absence of acceptable technology [Braithwaite:96].
- Problems due to collaboration
Security based wholly on the access control model starts breaking down as modern information systems grow in complexity and breadth. A major problem occurs when systems must serve internal needs as well as external collaborators. Collaborators are increasingly important in our complex enterprises, and cannot be viewed as enemies. They may be part of a supply chain, they may provide essential, complementary information, or may supply specialized services, beyond our own capabilities.
However, their roles are often specific, so that they do not fit neatly into the basic security categories. Distinct classes of collaborators typically have access rights that cannot be described by single global mandatory and discretionary model, but will have needs that both intersect and overlap with each other. To assure isolated access the stored data would have to split into an exponentially increasing number of cells as collaborations increase, creating problems for internal data contributor and users.
Furthermore, most collaborations arise after data-processing systems have been designed, installed, and placed into operation. That means that new security requirements are imposed dynamically on existing legacy systems. Creating and maintaining dedicated new systems with partial copies of base data for every new collaboration takes more time and resources than can be made available. Reconfiguring an existing partitioning of data to accommo-date a new external requirement is even more costly and awkward, and is likely to require modification of existing programs and retraining of staff who enter data.
- Partitioning of the information into cells
The process of assigning categories to information involves every person who creates, enters, or maintains information. When there are few basic cells, these originators can understand what is at stake, and will perform the categorization function adequately, although some errors in filing will still occur. When there are many cells, the categorization task becomes onerous and error prone. When new coalitions are created, and new collaborators must share existing information system, the categorization task becomes impossible.
There is impressive and productive research in technologies dealing with the first four requirements. We have secure encrypted communication, there are several commercial firewall products, we have means for adequate authentication, and database systems provide mappings to various levels of complexity. There are voluminous research results dealing with access control to provide mappings for multi-level security within a computer system [LuntEa:90]. Several simple implementations are commer-cially available, but have not found broad acceptance, likely because of a high cost/benefit ratio [Elseviers:94]. These systems do not accommodate very many distinct cells, and mainly support mandatory security levels [KeefeTT:89]. Leaks due to inference are still possible, and research into methods to cope with this issue is progressing [Hinke:88]. However, only few cases of exploiting inferential weaknesses have been documented, in [Neuman:00] we found only 2 in about 2000 instances of such computer misuse. However, other types of break-ins do occur.
Most breakins are initiated via legitimate access paths, since the information in our systems must be shared with potential customers and collaborators. In that case the first three technologies listed above provide no protection, and the burden falls on the mappings and the categorization of the information. In general, once an accessor is inside the system, protection becomes more difficult.
- Common Faults
Protection of internal information, once accessors have gained entry, differs from methods used for access control. Here one problem is that our software systems are far from perfect, and that performance and update requirements interfere with conservative software management and validation. We now do not consider enemies, bent on destruction, since we now deal with authenticated and identifiable collaborators. Relying on access mechanism to guarantee that no erroneous information can escape to those collaborators implies that that all data could be perfectly classified, has been entered into cells according to their classification, and that the retrieval software is perfect and. We now briefly consider software integrity, data integrity, and unforeseen effects of helpful software.
Having faultless software systems when there are millions of lines of code is an unaffordable task [Bellovin:95]. Most software faults do not affect security directly, although a single critical fault can be exploited by expert hackers and crackers. Vulnerabilities in commodity software are rapidly disseminated on the Internet. Use of secure software is discouraged by its high cost and poor maintainability. Multi-level secure software is not only more costly because of the additional code and its validation, but even more so because its availability lags the state-of-the art by about three years, causing easily a fourfold increase in cost of the complete system. Getting staff to maintain these systems is even more of a challenge, and poor maintenance will quickly negate the protection that these systems can provide. We see little use being made of multi-level secure systems.
We also indicated already that perfect isolation of data in complex and dynamic situations is nearly impossible. A single report can contain information that combines results that should be accessible and background information. When a new situation demands that a new collaboration be created, where, say background information should be withheld, it not feasible to scan all the information that should be made available for compliance with new security rules. A pragmatic solution is to create a new, specific information systems for the new coalition, one that replicates only the information required for these collaborators. This approach works for specific cases, but when over time many such combinations are needed, the system and its contents maintenance becomes a problem, and error prone as well.
Modern systems also try to be friendly and helpful. One aspect of being helpful is, that when a query is ill-posed, say it does not specify the desired data objects precisely, it will be generalized in order to retrieve related information that may have been intended. Such a helpful broadening will not take security constraints into account. Unfortunately, data found to be related may well have different access rights, and provide a collaborator with unintended information.
In summary, relying on access control alone is risky and costly. In secure manual system settings additional filters exist: the contents of a briefcase is inspected when leaving a secure facility and the cargo of a truck is checked when exiting a depot with valuable inventory, even though the people were authen-ticated, authorized on entry and constrained from freely moving around.
- A complementary technology
The solution we provide to the dilemma of access control is result checking [WiederholdBSQ:96]. In addition to conventional access control the result obtained by any information request is filtered before releasing them to the requestor. This task mimics the manual function of a security officer when checking the briefcases of authorized collaborating participants leaving a secure meeting, when exiting the secure facility. The TIHI approach also checks a large number of parameters about the release.
Multi-level secure systems may check for unwanted inferences when results are composed from data at distinct levels, but rely on level designations and matching record keys. Note that TIHI result checking does not depend on the sources of the result, so that it remains robust with respect to information categorization and misfilings.
- Filtering System Architecture
We incorporate result checking in a security mediator workstation, to be managed by a security officer. The security mediator system interposes security checking between external accessors and the data resources to be protected, as shown in Fig.1. It carries out functions of authentication and access control, to the extent that such services are not, or not reliably, provided by existing network and database services. Physically a security mediator is designed to operate on a distinct workstation, owned and operated by the enterprise security officer (S.O.). It is positioned as a pass gate within the enterprise firewall, if there is such a firewall. In our initial commercial installation the security mediator also provided traditional firewall functions, by limiting the IP addresses of requestors [WiederholdBD:98].
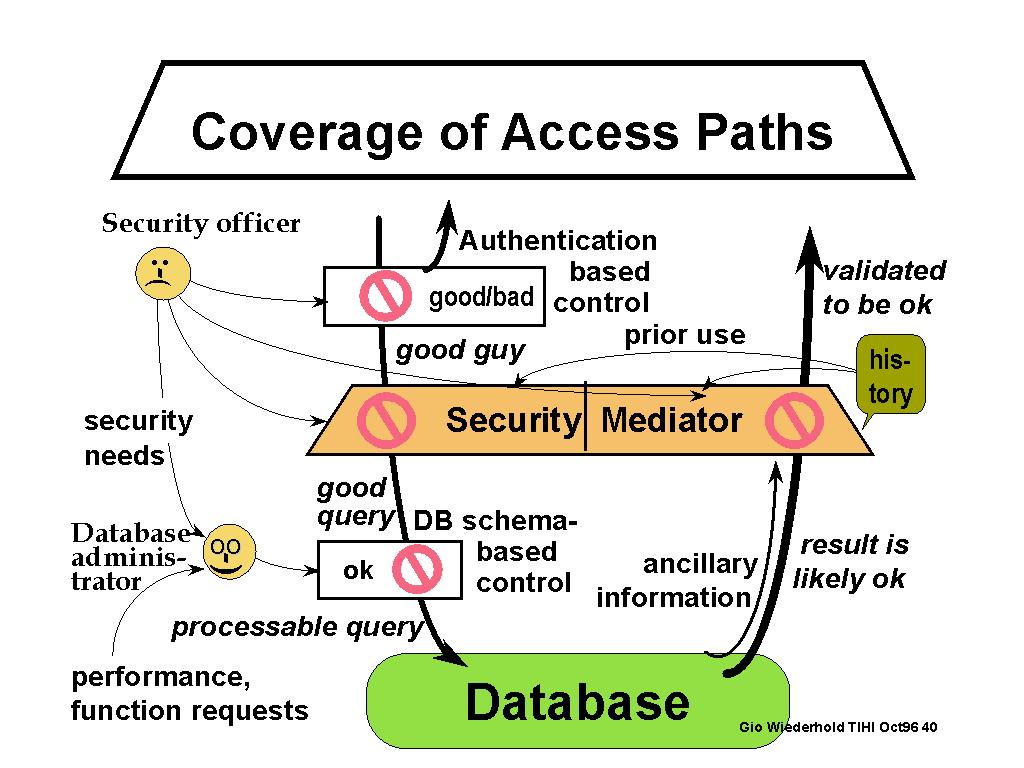
Figure.1. Architecture of a System protected by a Security Mediator
The mediator system and the source databases are expected to reside on different machines. The mediator system extends the functionality of the firewall, rather than that of the database systems. Thus, since all queries that arrive from the external world, as well as their results, are processed by the mediator, the databases behind a firewall need not be secure unless there are further internal require-ments. When combined with an integrating mediator, a security mediator can also serve multiple data resources behind the firewall [Ullman:96]. Combining multiple sources prior to result checking improves the scope of result validation.
The supporting databases can still implement their view-based protection facilities [GriffithsW:76]. These need not be fully trusted, but their mechanisms will add efficiency.
- Operation
Within the workstation is a rule-base system which investigates queries coming in and results to be transmitted to the external world. Any request and any result which cannot be vetted by the rule system is displayed to the security officer, for manual handling. The security officer decides to approve, edit, or reject the information interactively or as convenient. An associated logging subsystem provides an audit trail for all information that enters or leaves the domain. This log provides input to the security officer to aid in evolving the rule set, and increasing the effectiveness of the system.
The software of our security mediator is composed of modules that perform the following tasks
- If there is no firewall: Authentication of the requestor
- Determination of authorizations (clique) for the requestors role
- Processing of a request for information (pre-filtering) using the policy rules
- If the request is dubious: interaction with the security officer
- Augmentation of the query to obtain ancillary data
- Submission of certified request to internal databases (retrieval of unfiltered results)
- Processing of results and any ancillary data (post-filtering ) using the policy rules
- If the result is dubious: interaction with the security officer
- Writing query, origin, actions, and results into a log file
- Transmission of vetted information results to the requestor
Item 7, the post-processing of the possibly integrated results obtained from the databases, is the critical additional function. Such processing is potentially quite costly, since it has to deal thoroughly with a large volume and a wide variety of data. Applying such filters designed specifically for the problems raised in collaborations, as well as the impressive capabilities of modern computers, makes use of result filtering technology feasible. Having a rule-based system to control the filtering allows the security policies to be set so that a reasonable balance of cost to benefit is achieved. It will be described in the next section.
Having rules, however is optional. Without rules the TIHI mediator system operates interactively. Each query and each result will be submitted to the security officer. The security officer will view the contents on-line, and approve, edit, or reject the material for release. Adding rules enables automation. The extent of automation depends the coverage of the rule-set. A reasonable goal is the automatic processing of say, 90% of queries and 95% responses.
Unusual requests, perhaps issued because of a new collaboration, assigned to a new clique, will initially not have any applicable rules, but can be immediately processed by the security officer. Logging will still be automatic, and collects the instances on which eventually rules can be based. Subsequently, appropriate rules can be entered to reduce the interactive load on the officer.
Traditional systems, based on access control to precisely defined cells, require a long time to before the data are correctly partitioned, and when the effort is too high, may never be automated. Without automation, secure paper-based systems we encounter often take weeks for turn-around. In many other situation we are aware of, security mechanisms are bypassed when requests for information are deemed to be important. Keeping the security officer in control allows any needed bypassing to be handled formally. This capability recognizes that in a dynamic, interactive world there will always be cases that are not foreseen or situations the rules are too stringent. Keeping the management of exceptions within the system greatly reduces confusion, errors, and liabilities.
Even when operating automatically, the security mediator remains under the control of the enterprise since the rules are modifiable by the security officer at all times. In addition, logs are accessible to the officer, who can keep track of the transactions. If some rules are found to be to liberal, policy can be tightened. If rules are too stringent, as evidenced by an excessive load on the security officer, they can be relaxed or elaborated.
- The Rule System
The rules system is composed of the rules themselves, an interpreter for the rules, and primitives which are invoked by the rules. The rules embody the security policy of the enterprise. They are hence not preset into the software of the security mediator.
In order to automate the process of controlling access and ensuring the security of information, the security officer enters rules into the system. These rules trigger analyses of requests, their results, and a number of associated parameters. The interpreting software uses these rules to determine the validity of every request and make the decisions pertaining to the disposition of the results. Mediator system services help the security officer enter appropriate rules and update them as the security needs of the organization change.
The rules are simple, short and comprehensive. They are stored in a database local to the security mediator with all edit rights restricted to the security officer. Some rules may overlap, in which case the most restrictive rule automatically applies. The rules may pertain to requestors, cliques, sessions, databases tables or any combinations of these. The rules can remain simple and comprehensive because they rely on a set of primitive functions, described in the next section.
Rules are selected based on the authorization clique selected for the requestor. All the applicable rules will be checked for every request issued by the requestor in every session. An information request will be forwarded to the source databases only if it passes all tests. Any request not fully vetted is posted immediately to the log and sent the security officer. The failure message is directed to the security officer rather than to the requestor, so that the requestors will not see the failure and its cause. This prevents that the requestor make meaningful inferences from the failure patterns and rephrase the request to try to bypass the filter [KeefeTT:89].
The novel aspect of our approach is that security mediator checks outgoing results as well. This aspect is crucial since retrieval requests are inclusive, not exclusive selectors of content and may retrieve unexpected informa-tion. In helpful, user-friendly information systems getting more than asked for is considered beneficial, but from the security point-of-view getting more is not safe. Thus, even when the request has been validated, the results should also subject to screening. As before, all rules are enforced for every requestor and the results are released only if they pass all tests. Again, if the results violate a rule, a failure message is logged and sent only to the security officer.
- Primitives
The rules invoke executable primitive functions that operate on external requests, retrieved data, the log, and other information sources. As new security functions and technologies appear, or if specialized needs arise, new primitives can be inserted in the security mediator for subsequent rule invocation. We cannot expect that an initial system will contain all useful primitives. We do expect that all primitives will be sufficiently small and simple so that their correctness can be verified.
Primitives used in our implementations include:
- Limit access for clique to certain database table segments or columns
- Limit request to statistical (average, median, ..) information
- Provide number of data instances (database rows) used in the result as ancillary information
- Provide number of tables used (joins) for a result
- Limit number of requests per session
- Limit number of sessions per period
- Limit requests by requestor per period
- Block requests from all but listed sites
- Block delivery of results to all but listed sites
- Block receipt of requests by local time at request site
- Block delivery of results by local time at delivery site
- Constrain request to data which is keyed to requestor name
- Constrain request to data which is keyed to the requestor’s site name
- Filter selected and retrieved result terms through a clique-specific good-word list and disallow result on failure to match any term
- Disallow results containing terms in a clique-specific bad-word list
- Convert text by replacing identifiers with non-identifying surrogates [Sweeney:96]
- Convert text by replacing objectionable terms with surrogates
- Randomize responses for legal protection [Leiss:82]
- Extract text out of x-ray images (for further filtering)
- Notify the security officer immediately of failure reports
- Place failure reports only in the log
Not all primitives will have a role in all applications.
The most novel primitive is the filtering of retrieved terms against the good-word list. Such checking of the words appearing in results is costly in principle, but modern spell-checkers show that it can be done fairly fast. For this task we create clique-specific good-word lists by initially processing a substantial amount of approved results. In initial use the security officer will still get some false failure reports, due to innocent terms that are not yet in the good-word dictionary. Those are then added incrementally, so that in time the incidence of such failures becomes minimal.
For example, we have in use a dictionary for ophtamo-logy, to allow authenticated researchers in that specialized field to have access to patient data. That dictionary does not include terms that would signal, say HIV infection or pregnancies, information which the patients would not like to see released to unknown research groups. Also, all proper names, places of employment, etc. are effectively filtered.

Figure 2: Extract from the Security Officer's filtering review window.
Primitives can vary greatly in cost of application, although modern technology helps. Note that these primitives are to be written by system experts and must be validated in order to be trusted. Luckily, since the rule system provides fairly fine-grained modularity, the program modules defining the primitives will be modest in size, often quite small, so that existing software technology can be used to engender trust. However, the authors must be aware that providing security requires paranoid thinking, while most database functions tend to be generous.
Several of these primitives are designed to help control inference problems in statistical database queries [AdamW:89]. While neither we, nor any feasible system can prevent all leaks due to inference, we believe that careful management can make reduce the probability [Hinke:88]. Furthermore, providing the tools and material for analysis, as the log of all accesses and results, will reduce the practical threat [Sweeney:97]. The primitives to enforce dynamic limits on access frequencies have to refer to the log, so that efficient access to the log, for instance by maintaining a large write-through cache for the log, is important. Here again the function of traditional database support and security mediation diverges, since database transaction are best isolated, where as inference control requires history maintenance.
- Rule types
Rules relate requestors, or more often their cliques, to sets of primitives to be executed [Didriksen:97]. The rules are hence easy to comprehend, although must be limited in complexity. Currently none of our rules invoke directly other rules, although linkage can occur indirectly due to the effects of their actions.
The rules can be classified as set-up or maintenance rules, pre-processing (request validation) rules and post-processing (result validation) rules. Some primitives may be invoked by any class, but most primitives are specific to pre- or post-processing rules. Examples of primitives for pre-processing rules include the imitation of the number of queries per session, the number of queries for the clique, the session duration, etc. Post-processing rules can check against a minimum number of instances retrieved, restrictions on intersection of queries.
The rules designed to be easy to comprehend, to enable the officer to specify requirements and criteria accurately, and to be easy to enter into the system. All invoked rules affect the entire query transaction, so that whenever information is restricted, the requestors to not obtain any results. When requestors may obtain the information, they will see all of it, and not be misled or be motivated to make inferences about omitted data.
The requestors authenticated to access the system are grouped as cliques according to their roles. Authorizing rules may apply to one or more cliques. The security officer has the authority to add or delete requestors from cliques and to create/drop cliques. Similarly, columns in tables can be grouped into segments and request/results validations could be performed on segments. Database tables can be segmented. Request and results validations are then applied to such segments. Textual filtering can be performed on simple character type columns, on long fields of text, or on textual terms extracted from images. Filtering can also be applied to ancillary fields, say the patient’s ward in a hospital, so that for some wards patient data is treated differently, even if no ward information was requested.
- Logging
Throughout, the request texts, failures, as well as the result texts, images, and their sources, as well as actions taken by the security officer, are logged by the system for audit purposes. Having a security log which is distinct from the database log is important since:
- A database system logs all transactions, not just ex-ternal requests, and is hence confusingly voluminous
- Most database systems do not log attempted and failed requests fully, because they appear not to have affected the databases
- Reasons for failure of requests in database logs are implicit, and do not give the rules that caused them.
We provide user-friendly utilities to scan the security log by time, by requestor, by clique, and by data source. Offen-ding terms in the results are marked.
One must be aware that no system, except one that provides complete isolation, can be 100% foolproof. The provision of security is, unfortunately, a cat-and-mouse game, where new threats and new technologies keep arising. Logging provides the feedback that converts a static approach to a dynamic and stable system, one which can maintain an adequate level of protection. Logs will have to be inspected regularly to achieve stability.
Bypassing of the entire system and hence the log remains a threat. In must settings removal of information on portable media is easy. Only a few enterprises can afford to place controls on all personnel leaving daily for home, lunch, or competitive employment. However, having an effective and adaptable security filter removes the excuse that information had to be downloaded and shipped out because the system was too stringent for legitimate purposes. Some enterprises are considering limiting internal workstations to be diskless. It is unclear how effective this approach will be outside of small, highly secure domains in an enterprise. Such a domain will then have to be protected with its own firewall and a security mediator as well, because collaboration between the general and highly secure internal domains must be enabled.
- Role of the Security Officer
An important aspect of the architecture is that we recognize the specific role of a security officer, and provide a tool that is dedicated to the tasks that such an individual or group must carry out. While this organizational aspect may not be considered to be a significant scientific advance, it has crucial benefits to an enterprise that is concerned about the execution of its security policies.
Security responsibility is often assigned to individuals as a secondary task, and may interfere with the fulfillment of their primary task. For instance, when the responsibility for security is assigned to a database administrator, security may be compromised when demands for rapid and helpful retrievals are being satisfied. Helpful retrieval often means returning more, possibly related, information than the user formally requested. But the access control mechanism was based on that initial formulation, and does not cover all of the information that a helpful agent for the user might collect and return. The database administrator will be rewarded for the quality of the retrieval, and potential security leaks will be ignored.
A similar situation arises when responsibility for data security is given to the network administrator. Now the primary responsibility is availability and speed of the network. Bypassing of limiting and costly security provisions is a likely solution when users demand high-performance services.
- Current State and Further Work
Our initial demonstrations have been in the healthcare domain, and a commercial version of TIHI is now in use to protect records of genomic analyses in a pharmaceutical company. As the expectations for protection of the privacy of patient data are being solidified into governmental regulations we expect that our approach will gain popularity [Braithwaite:96]. Today the healthcare establishment still hopes that commercial encryption tools will be adequate for the protection of medical records, since the complexity of managing access requirements has not yet been faced [RindKSSCB:97]. Expenditures for security in medical enterprises are minimal [NRC:97]. Funding of adequate provisions in an industry under heavy economic pressures, populated with many individuals who do not attach much value to the privacy of others, will remain a source of stress.
Our earlier interactions with military applications have shown a clear need for result filtering. However, we have not yet had the opportunity to implement these concepts in such a setting.
- Non-textual contents
Identifying information is routinely deleted from medical records that are disseminated for research and education. However, here a gap exists: X-ray, MRI, and similar images accompany many research patient records, and these also include information identifying the patient. In a complementary project we have developed software which recognizes such text using wavelet-based decomposition and analysis, extracts it, and can submit it to the filtering system developed in TIHI. Information which is determined to be benign can be retained, and other text is effectively removed by omitting high-frequency components in the affected areas [WangWL:98].
We have also investigated our original motivating application area, namely manufacturing information. Here the simple web-based interfaces which are effective for the customer and the security officer interfaces in health care are not adequate. We have demonstrated interfaces for the general viewing and editing of design drawings and any attached textual information. In drawings significant text may be incorporated in the drawings themselves. When delivering an edited drawing electronically, one must also assure that there is no hidden information. Many design formats allow undo operations, which would allow apparently deleted information to reappear.
Before moving to substantial automation for collaboration in manufacturing, we will have to understand the parameters for reliable filtering of such information better. However, as pointed out initially, even a fully manual security mediator will provide a substantial benefit to enterprises that are trying to institute shared efforts rapidly.
- Intrusion Detection
Result checking can easily be performed invisibly, since the interaction with the contents is passive. This means that the technology may also be used to implement pure intrusion detection, by observing what is being taken out. Intruders that successfully penetrate the system may well be caught when removing results. For instance, if a simple terminology filter over results is in use, any removal of passwords will be caught. Since many attacks proceed in phases, having a security mediator system with result checking and logging in place provides a means for detection and then monitoring suspicious activities, without having to install new software. The intruder can be given an impression of success, while becoming a target for monitoring or cover stories.
We have not investigated primitives and rules specifically to detect intrusion. Here the rule system may direct the security mediator to respond seemingly normally, in order to gather more information for pursuit and prosecution. It appears that checking of output would be helpful in several cases that were recently published. For instance, it should have been obvious to a music web site that it shipped out 250 000 credit card numbers instead of an MP3 encoded song. Other violations, where classified material was moved to insecure computer systems in the process of backup or local study by authorized individuals, can be caught by monitoring the shipping out of infor-mation, even when access rights existed.
- Conclusions
Security mediation provides an architectural function as well as a specific service. Architecturally, expanding the role of a gateway in the firewall from a passive filter to an active pass gate service allows concentration of the responsibility for security to a specific node, owned by the security officer. Assigning responsibilities for security to database or network personnel, having a primary responsibility which can conflict with security concerns, is unwise. Existing services, as constraining views over databases, encryption for transmission in networks, password management in operating systems can be managed via the security mediator node.
The specific, novel service presented here, result checking, complements traditional access control. We have received a patent to cover the concept. Checking results is especially relevant in systems with many types of users, including external collaborators, and complex information structures. In such settings the requirement that systems that are limited to access-control impose, namely that all data are correctly partitioned and filed is not achievable in practice. Result checking does not address all issues of security of course, as protection from erroneous or malicious updates, although it is likely that such attacks will be preceded by processes that extract information.
The rules entered into the security mediator balance the need for preserving data security and privacy and for making data available. Data which is too tightly controlled reduces the benefits of information in collaborative settings. Rules which are too liberal can violate security and expectation of privacy. Having a balanced policy will require directions from management. Having a single focus for execution of the policy in electronic transmission will improve the consistency of the application of the policy.
The security mediator architecture does not solve all problems affecting security, of course. Secure systems still depend on a minimum level of reliability in the supporting systems. They cannot compensate for missing information or information that is not found because of misidenti-fication. In general, a security mediator cannot protect from inadvertent or intentional denial of information by a mismanaged database system.
- Acknowledgements
Research leading to security mediators was supported by an NSF HPCC
challenge grant and by DARPA ITO via Arpa order E017, as a
subcontracts via SRI International. Shelly Qian and Steve Dawson were
the PIs at SRI. Research to extract text out of images is supported by
NSF CISE as part of the Digital Library 2 program. Staff and students
who contributed concepts and code to a variety of implementations
include Michel Billelo, PhD, MD Stanford, Andrea Chavez, JD, MS
Stanford, and Vatsala Sarathy, MS Stanford. The commercial transition
was performed by Maggie Johnson, Chris Donahue, and Jerry Cain under
contracts with SST (www.2ST.com). Work on
editing and filtering graphics and images is due to Jahnavi Akalla, MS
Stanford, and James Z. Wang, PhD, Stanford Bioinformatics. We also
thank the organizers of the IEEE Information Assurance ands Security
Workshop, particularly Dr. John James, for their support.
- References
[AdamW:89] N.R. Adam and J.C. Wortmann,J.C.: "Security-Control Methods for Statistical Databases: a Comparative Study"; ACM Computing Surveys,Vol. 25 No.4, Dec. 1989.
[Bellovin:95] Steven M Bellovin, "Security and Software Engineering"; in B. Krishnamurthy, editor. Practical Reusable UNIX Software, John Wiley & Sons, 1995.
[Braithwaite:96] Bill Braithwaite: "National health information privacy bill generates heat at SCAMC"; Journal of the Ame-rican Informatics Association, Vol.3 no.1, 1996, pp.95-96.
[CastanoFMS:95] S.Castano, M.G. Fugini, G.Martella, and P. Samarati: Database Security; Addison Wesley Publishing Company - ACM Press, 1995, pp. 456
[CheswickB:94].William R.Cheswick and Steven M. Bellovin: Stalking the Wily Hacker; Addison-Wesley, 1994.
[Didriksen:97] Tor Didriksen: "Rule-based Database Access control – A practical Approach""; Proc. 2nd ACM workshop on Rule-based Access Control, 1997, pp.143-151.
[Elseviers:94] Elseviers Advanced Technology Publications: Trusted Oracle 7; Computer Fraud and Technology Bulletin, March 1994.
[FernandezEA:94] E. Fernandez et al., "A Model for Evaluation and Adminstration of Security in Object-oriented Databases"; IEEE Trans. on Knowledge and data Engineering, Vol.6 No.2, April 1994, pp. 275-292.
[GriffithsW:76] Patricia P. Griffiths and Bradford W. Wade: "An Authorization Mechanism for a Relational Database System"; ACM Trans. on Database Systems, Vol.1 No.3, Sept.1976, pp.242-255.
[He:97] J. He: "Performance and Manageability Design in an Enterprise Network Security System"; IEEE Enterprise Networking Miniconference 1997 (ENM-97), IEEE, 1997.
[Hinke:88] T. Hinke: "Inference Aggregation Detection in Database management Systems"; Proc. IEEE Symposium on Security and Privacy, Oakland CA, April 1988.
[JohnsonSV:95?] Johnson DR, Sayjdari FF, Van Tassel JP.: Missi security policy: A formal approach. Technical Report R2SPO-TR001, National Security Agency Central Service, July 1995.
[KeefeTT:89] T. Keefe, B.Thuraisingham, and W.Tsai: "Secure Query Processing Strategies"; IEEE Computer, Vol.22 No.3, March 1989, pp.63-70.
[LandwehrHM:84] Carl E. Landwehr, C.L. Heitmyer, and J.McLean: "A Security Model for Military Message Systems"; ACM Trans. on Computer Systems, Vol.2 No.3, Aug. 1984, pp. 198-222.
[LuniewskiEa:93] Luniewski, A. et al. "Information Organization Using Rufus" SIGMOD '93, ACM SIGMOD Record, June 1993, vol.22, no.2 p. 560-1
[LuntEa:90] Therea Lunt et al.: "The SeaView Security Model"; IEEE Trans. on Software Eng., Vol.16 No.6, 1990, pp.593-607.
[Neuman:00] Peter Neumann: Illustrative Risks to the Public in the Use of Computer Systems and Related Technology";
SRI International, May 2000, http://www.csl.ri.com/neumann/illustrative.html.
[Oracle:99] Oracle 8I Fine-grained Access Control, Oracle corporation, February 1999.
[QianW:97] Qian, XioaLei and Gio Wiederhold: "Protecting Collaboration"; abstract for IEEE Information Survivability Workshop, ISW'97, Feb.1997, San Diego.
[RindKSSCB:97] David M. Rind, Isaac S. Kohane, Peter Szolovits, Charles Safran, Henry C. Chueh, and G. Octo Barnett: "Maintaining the Confidentiality of Medical Records Shared over the Internet and the World Wide Web"; Annals of Internal Medicine 15 July 1997. 127:138-141.
[Rindfleisch:97] Thomas C. Rindfleisch: Privacy, Information Technology, and Health Care; Comm. ACM; Vol.40 No. 8 , Aug.1997, pp.92-100.
[SchaeferS:95] M. Schaefer, G. Smith: "Assured discretionary access control for trusted RDBMS"; in Proceedings of the Ninth IFIP WG 11.3 Working Conference on Database Security, 1995:275-289.
[Seligman:99] Len Seligman, Paul Lehner, Ken Smith, Chris Elsaesser, and David Mattox: "Decision-Centric Information Monitoring"; Jour. of Intelligent Information Systems (JIIS), Vol.14, No.1.; also at http://www.mitre.org/pubs/edge/june_99/dcim.doc
[Sweeney:96] Latanya Sweeney: "Replacing personally-identifying information in medical records, the SCRUB system"; Cimino, JJ, ed. Proceedings, Journal of the American Medical Informatics Association, Washington, DC: Hanley & Belfus, 1996, Pp.333-337.
[Sweeney:97] Latanya Sweeney: "Guaranteeing anonymity when sharing medical data, the DATAFLY system"; Proceedings, Journal of the American Medical Informatics Association, Washington DC, Hanley & Belfus, 1997.
[Ullman:97?] Jeffrey Ullman: Information Integration Using Logical Views; International Conference on Database Theory (ICDT '97) Delphi, Greece, ACM and IEEE Computer Society, 1997.
[WangWL:98] James Z. Wang, Gio Wiederhold and Jia Li: Wavelet-based Progressive Transmission and Security Filtering for Medical Image Distribution"; in Stephen Wong (ed.): Medical Image Databases; Kluwer publishers, 1998, pp.303- 324.
[WiederholdBC:98] Gio Wiederhold, Michel Bilello, and Chris Donahue: "Web Implementation of a Security Mediator for Medical Databases"; in T.Y. Lin and Shelly Qian:Database Security XI, Status and Prospects, IFIP / Chapman & Hall, 1998, pp.60-72.
[WiederholdBSQ:96] Gio Wiederhold, Michel Bilello, Vatsala Sarathy, and XiaoLei Qian: A Security Mediator for Health Care Information"; Journal of the AMIAecurity Mediator for Health Care Information"; Journal of the AMIA issue containing the Proceedings of the 1996 AMIA Conference, 27Oct1996, as Proceedings of the 1996 AMIAConference, Washington DC, Oct. 1996, pp.120-124.
[WiederholdEa:96] Gio Wiederhold, Michel Bilello, Vatsala Sarathy, and XiaoLei Qian: "Protecting Collaboration"; Proceedings of the National Information Systems Security Conference (NISSC'96), Baltimore MD, Oct. 1996, pp.561-569.