1997 Problem Set
The objective of the exam is to find out what you know about distributed systems and networks and to assess your ability to identify and develop solutions for problems that arise in this area. Note that the questions may have more than one "correct" answer, so be sure to provide justifications for your answers. State any assumptions you make when answering the questions. The points in parentheses are a rough indication of how many minutes to spend on each question. The exam is closed-book. Problem 1 (30 Points) Let's say you are designing a distributed file system. Your system has 25 workstation clients and one server. Each workstation has a modest amount (32 megabytes) of memory. This is not enough memory to cache everything a client accesses. The server has 1 gigabyte of memory. The machines are all connected to a low-latency 100Mbit Ethernet subnet. The workload for the system is typical of a UNIX software development environment (lots of temporary files, most files are small, but there are some simulations running that use huge files). Assume you have a cache consistency protocol that allows you to maintain consistency between caches and between caches and the disk with only a small amount of overhead. Unless forced to do so by a particular application, Files are not written synchronously to disk but are instead caches in memory for up to 30 seconds and written asynchronously from the cache to disk.You have two configurations you're currently considering.
Configuration 1: You buy a 1 gigabyte disk for each client, and each client has its own /, /bin, /usr/bin, /tmp, and /usr/local on its local disk. It also has its primary user's home directory on its local disk. The clients can cache file system blocks in main memory, and use this cache for files they read from and write to their local disks as well as any files they read from and write to the server. The server also has a big cache for data blocks it reads from and writes to its disk.
Configuration 2: The clients have no local disks and access all files from the server, which has a huge amount of disk space. They cache file blocks in their local memories. The server also caches file blocks in its memory for files read from its disk or written to the server from the clients. These files are eventually written to disk.
Please evaluate these configurations based on the following metrics:
- performance (how fast is the file system?)
- availability (how available is the file system if something crashes?)
- reliability (how much data may be lost if something crashes?)
- ease of system administration (how hard is the system to maintain?)
Problem 2 (15 Points) Consider time synchronization in the Internet. Let's say you are concerned with synchronization between two machines. Assume that the clocks on the two machines are equally precise. Also assume that they tick at the same frequencies. The only problem is that the clocks on the two machines may be offset compared to each other (e.g., the first thinks it’s 4am at exactly the same time the other thinks it’s 4:01am).
The figure below shows time stamps (taken locally on a machine), of a round trip packet sent between the two machines. T4 is the most recent time stamp, and T1 is the oldest.
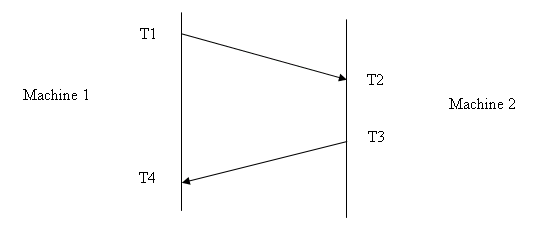
(Hint: this topic was covered in the paper by David Mills on the reading list titled "Internet Time Synchronization: the Network Time Protocol.")
- Given these time stamps, what is the round-trip delay between the machines? (This counts only time on the wire, not time on the machine corresponding to the packet.)
- What is the clock offset between the machines?
Problem 3 (15 Points) Causally-ordered communication makes sure that messages are delivered in an order that is consistent with the potential causal dependencies between messages. For example, if a process P1 sends a message M1 to other processes, and this causes process P2 to send message M2 to the processes, then these two messages are causally related and should be received in the same order by all the participating processes. Protocols that ensure such ordered and reliable message delivery are considered by some to be a foundation upon which we can build reliable distributed systems. Unfortunately, ensuring such reliable ordered message delivery isn’t enough to ensure a reliable distributed system in many cases.
- Consider the following distributed system: Several devices communicate over a network using causally-ordered communication. A few of these devices are also connected separately to a database that is not on this network. What could go wrong in such a system even if we ensure causal ordering of messages over the network?
- What is an example of something else that could go wrong, either in this or some other distributed system whose reliability depends upon causally-ordered messages?