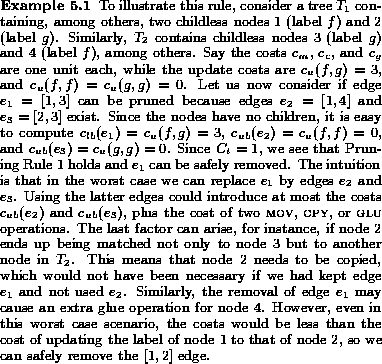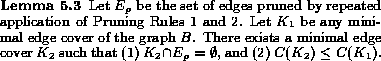We now use the upper and lower bound functions for the cost of an edge
as defined above to introduce the pruning rules we use to reduce the
size of the induced graph of the two trees being compared. Let ![]() be any edge in the induced graph. Let
be any edge in the induced graph. Let ![]() be any edge
incident on m, and let
be any edge
incident on m, and let ![]() be any edge incident on n.
Intuitively, our first pruning rules removes an edge with a lower
bound cost that is so high that it is preferable to match each of its
nodes using some other edge that has a suitably low upper bound cost.
be any edge incident on n.
Intuitively, our first pruning rules removes an edge with a lower
bound cost that is so high that it is preferable to match each of its
nodes using some other edge that has a suitably low upper bound cost.
Our second pruning rule (already illustrated in Section 3) states that if it is less expensive to delete a node and insert another, we do not need to consider matching the two nodes to each other. More precisely, we state the following:
Note that the above pruning rules are simpler to apply if we let ![]() and
and ![]() be the minimum-cost edge incident on m and n,
respectively. The following lemma, proved in
[&make_named_href('',
"node21.html#bbdiffExtended","[CGM97]")], tells us that the pruning rules are
conservative:
be the minimum-cost edge incident on m and n,
respectively. The following lemma, proved in
[&make_named_href('',
"node21.html#bbdiffExtended","[CGM97]")], tells us that the pruning rules are
conservative:
The pruning phase of our algorithm consists of repeatedly applying Pruning Rules 1 and 2. Note that the absence of edges raises the lower bound function, and lowers the upper bound function, thus possibly causing more edges to get pruned. Our algorithm updates the cost bounds for the edges affected by the pruning of an edge whenever the edge is pruned. By maintaining the appropriate data structures, such a cost-update step after an edge is pruned can be performed in O(log n) time, where n is the number of nodes in the induced graph.