| S a t y a m V a g h a n i | |||
 |
% Photos, etc. % < Contact Me > | |
| ~ Source code, apps, pointers, etc ~ |
InfoSpaces
A Large Scale Content Classification and Dissemination System
InfoSpaces
A Large Scale Content Classification and Dissemination System
Satyam Vaghani, Michael Michael, Jairam Ranganathan, Sujata
Kodgire
{svaghani, michmike, jairam, sujk} @ cs.stanford.edu
Conventional information delivery models on the Internet need the person to know what he/she is looking for and to own an information delivery end-point (for e.g.: a PDA or a computer connected to the Internet, a TV etc.). This mechanism is user centric and guarantees (at least in theory) that all the information that is delivered is relevant to the person. We found two shortcomings with this mechanism: The user does not always know what to look for; and the content that can be delivered is often restricted to the type of delivery mechanism and delivery endpoint We propose to implement an alternative information dissemination model that sheds off a few characteristics of personalized information delivery in the favor of being ubiquitous, cost-effective and demographically targeted.
Abstract
Public information routing and delivery is fraught with difficulty. The functionality of large-scale publish/subscribe systems is often restricted by the choice of delivery mechanism and delivery end-point. Scheduling predicates do not hold globally over concurrent content delivery streams to diverse end-points that share resources to disseminate information. We have implemented an alternative information dissemination model that sheds off a few characteristics of personalized information delivery in order to provide ubiquitous, cost-effective and demographically targeted information. We try to characterize some important abstractions to achieve these goals and discuss a scheduler that allows the resources of a set of end-points to be grouped to display information of common interest.
Motivation
InfoSpaces strives to present information in a different perspective: Make information ubiquitous so that a person absorbs new information without actually realizing it or making a conscious effort to fetch it. Information should be all pervasive and not limited to a 'available on request' format.
More Info...
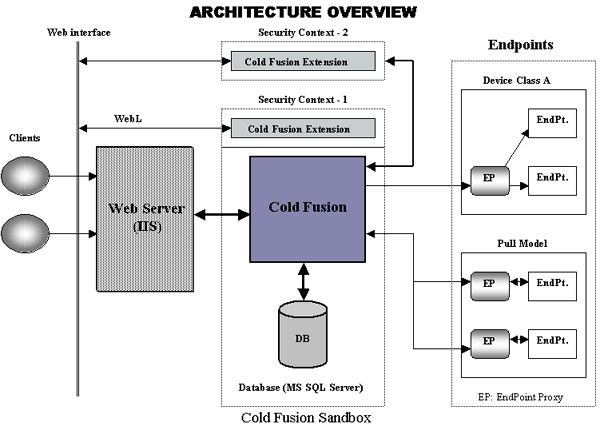
Most publish/subscribe systems must deal with the issue of categorizing and disseminating large amounts of information to a group of heterogeneous end-points in a cost-effective and scalable manner. Previous work in such systems has focused on efficient multicasting of information to the end-points and content-based information routing to interested subscribers. These systems assume a common application-level communication substrate (in most of the cases, the Internet). We designed an end-to-end solution, called InfoSpaces, for large-scale classification and dissemination of in-formation. InfoSpaces is designed to retrieve/accept information from various active and passive sources, classify it and route it to diverse physical devices. These devices, which we refer to as end-points, have differ-ent display capabilities and modes of connectivity. InfoSpaces handles a large amount of information that contends for a limited number of display slots on end-points. This required us to design a scheduler that makes in-time delivery guarantees for high-priority content, preserves the priority order of large information sets, minimizes persistent state maintenance, and does not impose too much overhead to the system.
Project Document Repository