In this section we consider the Good Matching problem,
motivated in Section 3. We want to find an
appropriate matching between the nodes of trees 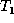 and
and 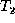 that
can serve as input to Algorithm EditScript. In applications
in which the data has object-ids or keys, we can match nodes using
these object-ids or keys. However, as described in
Section 1, our focus here is on applications where
information may not have keys or object-ids that can be used to match
``fragments'' of objects in one version with those in another. We use
the term keyless data for hierarchical data that may not have
identifying keys or object-ids.
that
can serve as input to Algorithm EditScript. In applications
in which the data has object-ids or keys, we can match nodes using
these object-ids or keys. However, as described in
Section 1, our focus here is on applications where
information may not have keys or object-ids that can be used to match
``fragments'' of objects in one version with those in another. We use
the term keyless data for hierarchical data that may not have
identifying keys or object-ids.
When comparing versions of keyless data, there may be more than one
way to match objects. Thus we need to define matching criteria
that a matching must satisfy to be considered ``good'' or appropriate.
In general, the matching criteria will depend on the domain being
considered. One way of evaluating matchings that is desirable in many
situations is to consider the minimum cost edit scripts that conform to
the matchings (and transform 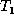 into
into 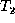 ). Intuitively, a
matching that allows us to transform one tree to the other at a lower
cost is a better matching. Formally, for matchings M and
). Intuitively, a
matching that allows us to transform one tree to the other at a lower
cost is a better matching. Formally, for matchings M and 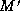 , we
say that M is better than
, we
say that M is better than 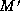 if a minimum cost edit script
that conforms to M is cheaper than a minimum cost edit script that
conforms to
if a minimum cost edit script
that conforms to M is cheaper than a minimum cost edit script that
conforms to 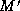 . Our goal is to find a best matching, that
is, a matching M that satisfies the given matching criteria and such
that there is no better matching
. Our goal is to find a best matching, that
is, a matching M that satisfies the given matching criteria and such
that there is no better matching 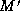 that also satisfies the
criteria.
that also satisfies the
criteria.
Unfortunately, if our matching criterion only requires that matched
nodes have the same label, then finding the best matching has two
difficulties. The first difficulty is that many matchings that satisfy
only this trivial matching criterion may be unnatural in certain
domains. For example, when matching documents, we may only want to
match textual units (paragraphs, sections, subsections, etc.) that
have more than a certain percentage of sentences in common. The
second difficulty is one of complexity: the only algorithm known to us
to compute the best matching as defined above (based on
post-processing the output of the algorithm in [ZS89]) runs in
time 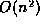 where n is the number of tree
nodes [Zha95]. To solve the first difficulty, we
restrict the set of matchings we consider by introducing stronger
matching criteria, as described below. These criteria also permit us
to design efficient algorithms for matching. In the rest of this
section, we describe some matching criteria for keyless data, using
structured documents as an example.
where n is the number of tree
nodes [Zha95]. To solve the first difficulty, we
restrict the set of matchings we consider by introducing stronger
matching criteria, as described below. These criteria also permit us
to design efficient algorithms for matching. In the rest of this
section, we describe some matching criteria for keyless data, using
structured documents as an example.